
Extracting Web Data Efficiently with Python
Step-by-Step Instructions for Using Beautiful Soup
Best Practices for Ethical Web Scraping
Introduction to Web Scraping and Its Applications
Setting Up Beautiful Soup for Web Scraping in Python
Parsing HTML and Extracting Data from Websites
Handling Challenges in Web Scraping (CAPTCHAs, Dynamic Content)
Why Use Beautiful Soup for Web Scraping?
Writing Python Scripts to Automate Web Data Extraction
Formatting and Cleaning Extracted Data
Avoiding Legal Issues and Following Web Scraping Guidelines
Experts estimate 80% of global data is unstructured – web content, audio, video, images, documents. Extracting insights from this chaos requires a methodical approach. Web scraping meets that need, converting raw web data into structured form for analysis. In this blog, we’ll dive into how to do just that using Python and the popular Beautiful Soup library.
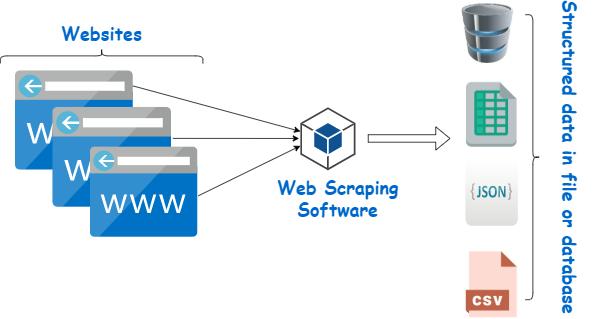
Web scraping automates data collection from websites, typically stored in HTML. It targets specific elements or broad datasets, delivering structured output ready for use in further analysis.
Web scraping has uses across industries in things like price monitoring, market research, sentiment analysis, news tracking, email marketing, e-commerce price comparison, and machine learning data collection. Techniques vary and different people use different technologies including manual copy-pasting, text matching, HTTP programming, HTML parsing, DOM parsing, vertical aggregation, and semantic recognition. For this blog, we’ll focus on HTML parsing with Python for its efficiency and accessibility.
Steps Involved in Web Scraping

Why Python Excels?
Developers love Python because of its unique features and simple code format. Python’s clear syntax and rich libraries make it ideal for scraping. Its key tools include:
- Beautiful Soup: Parses HTML and XML.
- Mechanical Soup: Handles website interactions.
- Scrapy: High-speed scraping framework.
- Selenium: Manages JavaScript sites.
- Requests: Simplifies HTTP requests.
- LXML: Fast XML/HTML processing.
- URLlib: Opens URLs.
- Pandas: Organizes scraped data.
Why Developers Choose Beautiful Soup?
Beautiful Soup’s ease often makes it the go-to Python library for web scraping. Beautiful Soup excels for scraping HTML and XML. A practical, reliable choice, Beautiful Soup is:
- Simple: Easy parsing interface.
- Robust: Handles messy HTML.
- Flexible: Multiple parser options (lxml, html5lib, html.parser).
- Supported: Strong documentation and community.
- Free: Open-source.
Comparing Beautiful Soup with Scrapy and Selenium
| Beautiful Soup | Scrapy | Selenium |
| This is mainly used for web scrapping | This is mainly used for web scrapping | This is mainly used for web testing, API testing |
| Work well with HTML and XML | Work well with HTML and XML | Work well with JavaScript only |
| Requires dependencies | Not Requires dependencies | Not mean to be a web scrapper |
| Scrapping speed is fast | Scrapping speed is very fast | Testing speed is fast |
| Easy to set up | Difficult to set up | Easy to set up |
| Easy to learn | Complex to learn | Easy to learn |
Web Scraping Using Beautiful Soup – Steps Involved
Step1
Install the required python packages in command prompt.
pip install requests
pip install html5lib
pip install bs4Step 2
Import all required 3rd party libraries in python script.
from bs4 import BeautifulSoup
import requests
import pandas as pdStep 3
Find the URL that you want to scrape.
For example, we are going to scrape top 250 movies – IMDB.

Step 4
Once we get the URL link then we have to store it in variable.
url = 'http://www.imdb.com/chart/top'Here “url” refers to user defined variable’
(Note: We can use the same base URL for multiple pages (differing only by a page extension at the end) and extract all the data using a for loop.)
Step 5
After storing the URL in a variable, fetch the HTML code from that URL. In your browser, open the webpage, right-click, and select “Inspect” to view the HTML code.
Browser > open HTML-link > right click > inspect > HTML code
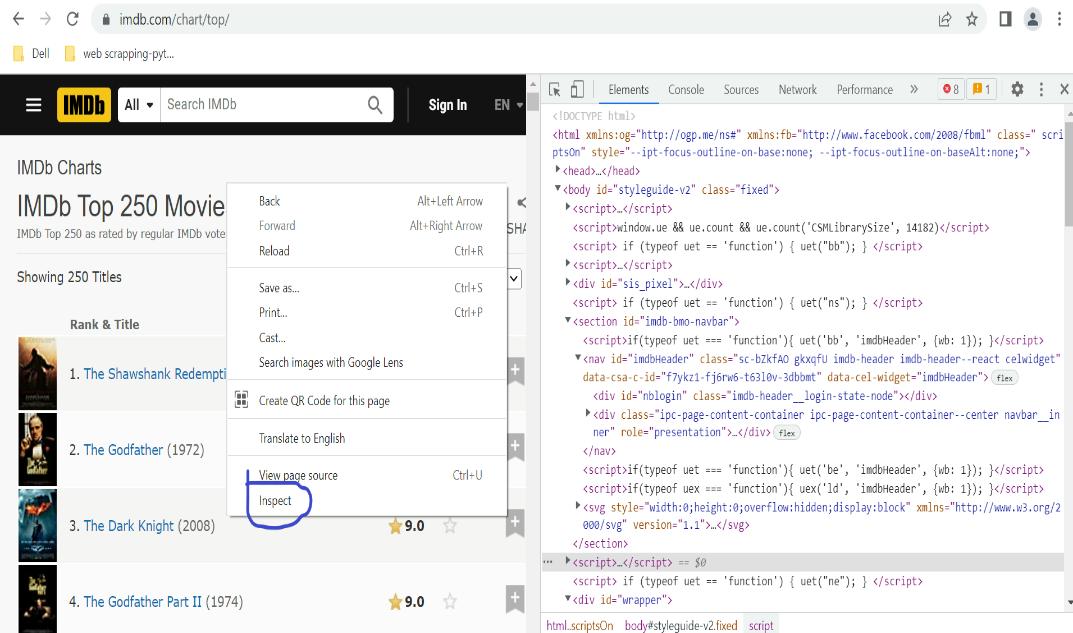
Once the “Inspect” tab is clicked, the browser’s inspector tool opens, displaying the HTML structure of that specific webpage.
Step 6
We have to extract the data from HTML page.
- Get the details of the URL we need to use requests library to get the information of that URL.
response = requests.get(url)Here “response” is user defined variable
- We have to use BeautifulSoup library to extract html content with passing html.parser and store it in variable.
soup = BeautifulSoup(response.text, "html.parser")Here “html.parser” parses tokenized input into the document, building up the document tree.
- Once we get the HTML code then we have to figure out all the information present in that code with respect to which objects or column in web page. The data is usually nested in tags.
- We must pass the particular tags and parameters with respect to particular column data present in that web page with the help of html codes using soup.prettify (prettifies the HTML with proper alignment).
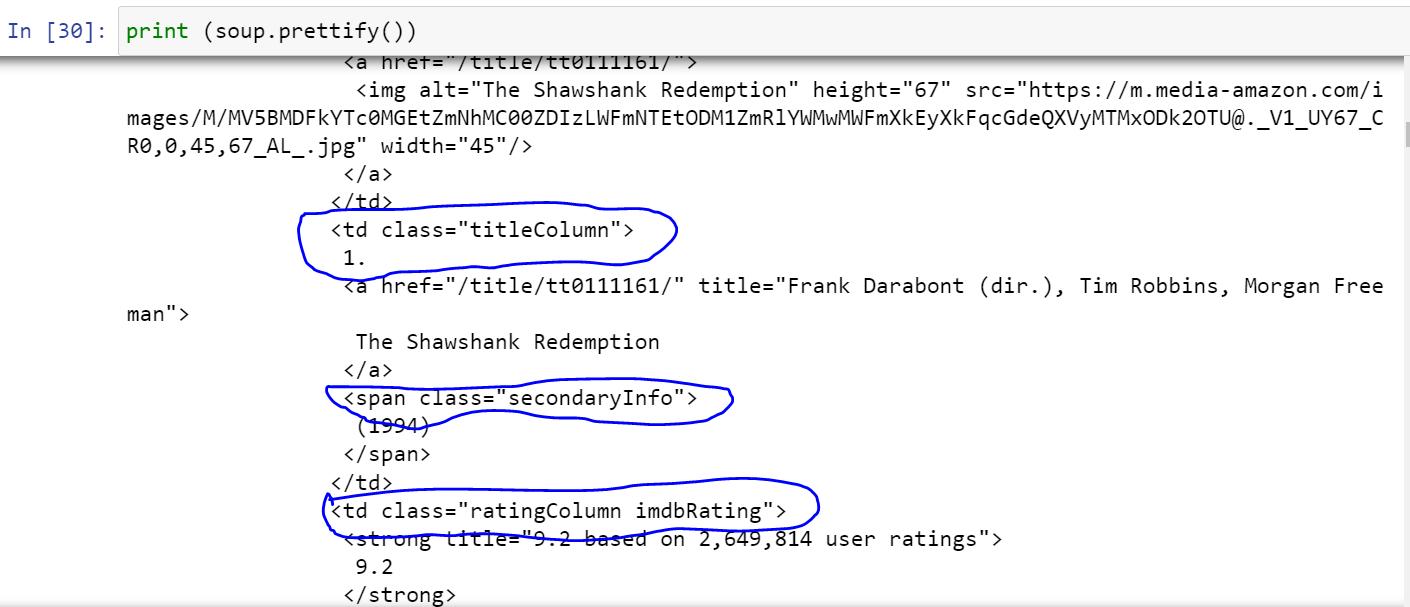
In the above image we can see that tags are present between “< >”. Here “<td>” is nothing but “Table Data cell element” tag name related to table that contain data, ‘< a>’ is anchor tag having attributes like ‘href’ and‘title’.
- We have to create an empty list for storing all columns information.
# create a empty list for storing
# movie information
list = []- Pass the information of tags, arguments and parameters in mentioned column variable
movies = soup.select('td.titleColumn')
crew = [a.attrs.get('title') for a in soup.select('td.titleColumn a' a')]
ratings = [b.attrs.get('data-value') for b in soup.select('td. posterColumn span [name=ir]')]Here movies, crew, rating are user defined column variables
- Once the information is stored in the columns, then we have to do the necessary transformations in order to get rid of the unnecessary characters in the strings (For example: append, split, replace)
movie_string = movies [index].get_text()
movie = ('.join(movie_string.split()).replace('.', ''))- After the necessary transformation we have to store the data into one variable and pass that variable in mentioned empty list.
data = {"place": place,
"movie_title": movie_title,
}
list.append(data)Step 7
Run the code and extract the data.
# printing movie details with its rating.
for movie in list:
print(movie['place'], '-', movie ['movie_title'], '('+movie [ 'year'] + ') -', 'Starring:', movie['star_cast'], movie['rating'])The output of the above code is

Step 8
Store the data into required format. After extracting data, you might want to store it in a format depending on your requirements. For this example, we will store the extracted into a CSV (Comma Separated Value) format.
df = pd.DataFrame(list)
df.to_csv('Top IMDB_250_Movies.csv',index=False)|The output of the above code is
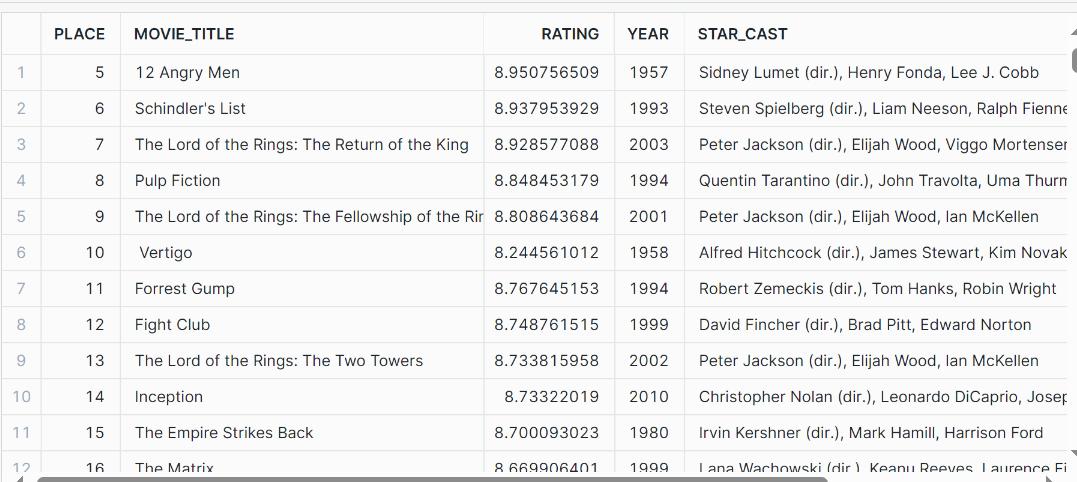
In Image 1 we can see the html data stored in semi structured format and after scraping we can get our data into structured format as we can see it in Image 2.
In this blog, we’ve covered web scraping with Beautiful Soup—installation, HTML retrieval, parsing, and data extraction. Web scraping can be a powerful tool for data analysis, but it is important to be ethical and follow best practices when scraping websites. Always make sure to check a site’s terms of service before scraping. With Beautiful Soup, you’re equipped to proceed effectively and responsibly.
