








 Media Coverage
Media Coverage Press Release
Press ReleaseLeveraging Parent-Child Relations for Efficient Data Management
Exploring Elasticsearch’s Parent-Child Feature for Hierarchical Data
Elasticsearch provides a flexible search and analytics engine capable of handling complex data relationships. One of its most powerful yet often misunderstood capabilities is the ability to define parent-child connections between documents. In this comprehensive guide, we explore the intricacies of modeling and querying hierarchical data using Elasticsearch’s parent-child feature. Whether you need to search reports based on metadata, analyze logs by customer, or simply understand table-like joins, this guide aims to uncover the art of representing and retrieving multi-level relational data. We compare alternatives like nesting and denormalization and offer best practices for optimization based on real-world use cases.

By the end of this guide, you will have mastered the techniques needed to elegantly handle intricate data connections within your Elasticsearch implementation.
What is Elasticsearch?
Elasticsearch is a distributed, RESTful, open-source search and analytics engine that efficiently centralizes your data for rapid search capabilities, tailor-made relevance, and seamlessly scalable powerful analytics.
Understanding Parent-Child Relations in Elasticsearch
Managing Hierarchical Data with Elasticsearch
Enhancing Search Capabilities with Parent-Child Relations
Implementing Parent-Child Relations in Your Elasticsearch Index
Purpose & Benefits

Search Engine:
Elasticsearch is primarily used as a search engine, allowing users to search and retrieve data quickly and efficiently. It supports full-text search, enabling users to search for words or phrases within large datasets.

Real-time analytics:
You can ingest and analyze data in real-time with Elasticsearch, making it perfect for use cases like fraud detection, anomaly detection, and operational monitoring.

Geospatial Search:
Elasticsearch supports geospatial data types, allowing you to search for data based on location. This is useful for applications like real estate search, logistics, and delivery tracking.

Text Analysis:
It supports advanced text analysis features, including tokenization, stemming, and synonyms, which enhances the accuracy of search results.

Log and Event Data Analysis:
Elasticsearch is commonly used for analyzing and searching through log and event data. It is capable of handling and indexing large volumes of log data in real-time.

Scalability:
Elasticsearch can be easily scaled to handle large volumes of data by adding more nodes to your cluster, making it suitable for handling growing amounts of data and increasing workloads.

Flexibility:
Elasticsearch allows for real-time indexing, meaning that data is searchable immediately after being indexed.

Real-Time Indexing:
Elasticsearch allows for real-time indexing, meaning that data is searchable immediately after being indexed.

Performance:
Elasticsearch is incredibly fast, able to return search results in milliseconds. This is crucial for applications where speed is essential.

Open-source:
Elasticsearch is an open-source project, which means it’s free to use and modify. This makes it a cost-effective solution for businesses of all sizes.

Integrations:
Elasticsearch integrates with a wide range of other tools and technologies, such as Logstash for data ingestion and Kibana for visualization, making it easy to build powerful data pipelines and applications.

Ease of Use:
Elasticsearch provides a RESTful API and is relatively easy to set up and use. It also has client libraries for various programming languages.
While Elasticsearch isn’t designed to be a relational database, it provides several strategies to handle relational data.
Denormalization vs Nested Objects vs Parent-Child Relationships
Before we begin, let’s compare parent-child relationships with other approaches.
| Denormalization | Nested Objects | Parent-Child Relationships | |
|---|---|---|---|
| Concept | Denormalized data by including all the necessary information within a single document | Embed related data as nested objects within documents | Establish parent-child connections between documents |
| Data Structure | Single document | Single document | Separate parent and child documents |
| Best for | Simple structures and fast retrieval | Hierarchical structures and complex queries | Tree-like relationships and explicit data connections |
| Pros |
|
|
|
| Cons |
|
|
|
Key Considerations
- Denormalization requires careful planning to avoid data inconsistencies and redundancy.
- Nested objects may not be ideal for very deep data structures due to performance considerations.
- Parent-child relationships offer a clear representation of data connections but can be more complex to manage.
Introduction to Parent-Child Relations
Benefits of Using Parent-Child Relations in Elasticsearch
Best Practices for Working with Parent-Child Data
Advanced Techniques for Optimizing Elasticsearch Queries
Ultimately, the best approach depends on the specific characteristics of your data and query patterns. Consider the trade-offs of each method and choose the one that best balances performance, data integrity, and flexibility for your use case. It’s essential to carefully consider these factors and test different approaches to determine the most suitable one.
Installing Elasticsearch
Refer to the official Elasticsearch documentation for installation and to run locally.
Implementing Multi-Level Parent-Child Joins in Elasticsearch
Let’s consider a hospital use case with three multi-level relations data.
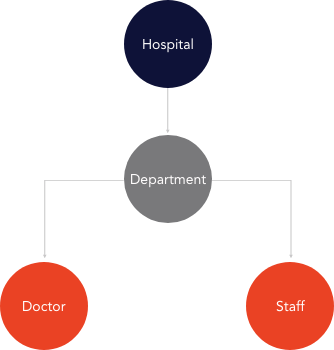
Data Structure

We will be using Kibana dev tools to interact with the REST APIs of Elasticsearch.
Create Index
PUT /hospital-index-01
{
"mappings": {
"properties": {
"join_field": {
"type": "join",
"relations": {
"hospital": "department",
"department": ["doctor", "staff"]
}
}
}
}
}The join data type is a special field that creates parent/child relation within documents of the same index. The relations section defines a set of possible relations within the documents, each relation being a parent name and a child name.
Upload Documents
Adding a hospital (parent document):
PUT /hospital-index-01/_doc/1
{
"hospital_name": "General Hospital", // parent - field and value
"join_field": "hospital" // parent name
}Adding a department (child Document): Indexing a child document requires a routing value equal to the parent document ID.
PUT /hospital-index-01/_doc/2?routing=1
{
"department_name": "Cardiology", // child - field and value
"join_field": {
"name": "department", // parent name
"parent": 1 // parent doc id
}
}Adding a doctor (Grandchild Document):Indexing a grandchild document requires a routing value equal to the grandparent document ID.
PUT /hospital-index-01/_doc/3?routing=1
{
"doctor_name": "Dr. Smith", // grandchild - field and value
"join_field": {
"name": "doctor", // child name
"parent": 2 // child doc id
}
}Adding a staff (Grandchild Document): Indexing a grandchild document requires a routing value equals to the grandparent document ID.
PUT /hospital-index-01/_doc/4?routing=1
{
"staff_name": "Alex", // grandchild - field and value
"join_field": {
"name": "staff", // child name
"parent": 2 // child doc id
}
} Adding another set of data:
PUT /hospital-index-01/_doc/5
{
"hospital_name": "Eye Hospital", // parent - field and value
"join_field": "hospital" // parent name
}PUT /hospital-index-01/_doc/6?routing=5
{
"department_name": "Ophthalmology", // child - field and value
"join_field": {
"name": "department", // parent name
"parent": 5 // parent doc id
}
}PUT /hospital-index-01/_doc/7?routing=5
{
"doctor_name": "Dr. Mohan", // grandchild - field and value
"join_field": {
"name": "doctor", // child name
"parent": 6 // child doc id
}
}PUT /hospital-index-01/_doc/8?routing=5
{
"staff_name": "Silva", // grandchild - field and value
"join_field": {
"name": "staff", // child name
"parent": 6 // child doc id
}
}Querying
Retrieve parent documents by child query.
GET /hospital-index-01/_search
{
"query": {
"has_child": {
"type": "department",// child
"query": {
"term": {
"department_name.keyword": {
"value": "Cardiology"
}
}
}
}
}
}Retrieve parent documents by grandchild query.
GET /hospital-index-01/_search
{
"query": {
"has_child": {
"type": "department", // child
"query": {
"has_child": {
"type": "doctor", // grandchild
"query": {
"term": {
"doctor_name.keyword": {
"value": "Dr. Mohan"
}
}
}
}
}
}
}
} Retrieve parent documents, child documents and grandchildren documents:
GET /hospital-index-01/_search
{
"query": {
"has_child": {
"type": "department", // child
"inner_hits": {},
"query": {
"has_child": {
"type": "doctor", // grandchild
"inner_hits": {},
"query": {
"term": {
"doctor_name.keyword": {
"value": "Dr. Mohan"
}
}
}
}
}
}
}
}Retrieve child documents by parent query:
GET /hospital-index-01/_search
{
"query": {
"has_parent": {
"parent_type": "hospital", // parent
"query": {
"term": {
"hospital_name.keyword": {
"value": "General Hospital"
}
}
}
}
}
}Retrieve grandchildren documents by parent and child query:
GET /hospital-index-01/_search
{
"query": {
"has_parent": {
"parent_type": "department", // child
"query": {
"has_parent": {
"parent_type": "hospital", // parent
"query": {
"term": {
"hospital_name.keyword": {
"value": "Eye Hospital"
}
}
}
}
}
}
}
} Remember to adapt these queries based on your specific use case and requirements. This example provides a simplified representation of the hospital, department, doctor, and staff entities using Elasticsearch’s parent-child approach.
Best Practices
Here are some best practices for using parent-child relationships in Elasticsearch:
Mapping and Indexing:

Define clear parent and child types:
Clearly identify the parent and child types in your mappings. Use descriptive names and consider prefixing child types for easier identification.

Specify appropriate field types:
Choose appropriate data types for fields in both parent and child documents. Use keyword for unique identifiers, text for searchable fields, and numeric types for quantitative data.

Include the “_parent” field:
Ensure all child documents have a dedicated “_parent” field referencing the parent document’s ID.

Optimize indexing:
Configure indexing settings like number of shards and replicas based on your data volume and query needs. Consider using warm or cold tiers for less frequently accessed data.
Queries and Joins:
Utilize has_child query:
Employ the has_child query to efficiently search for parent documents based on their child documents and has_parent query to efficiently search for child documents based on their parent documents.

Leverage aggregations:
Use aggregations to gain insights across relationships, such as counting doctors per department or analyzing patient diagnoses within an admission.

Utilize filtering and sorting:
Utilize filtering and sorting capabilities within nested queries to refine and organize your results.

Plan for performance:
Optimize joins by pre-routing child documents to the same shard as their parent. Monitor query performance and adjust mappings or settings as needed.

Use the _source Field Judiciously:
Consider disabling the _source field for parent/child documents if you don’t need to retrieve the specific fields from the documents. This can save storage space.

Be Mindful of Query Complexity:
Parent-child relationships can introduce query complexity, especially when performing searches or aggregations across multiple levels. Test your queries thoroughly to ensure they meet performance expectations.
General Practices:

Start simple:
Begin with simple parent-child relationships and gradually add complexity as needed.

Document your schema:
Document your mapping structure and naming conventions for reference and future modifications.

Consider alternatives:
In some scenarios, alternatives like nested objects or denormalization might be more suitable. Evaluate the specific requirements of your use case and choose the approach that aligns with your needs.

Monitor and maintain:
Regularly monitor your Elasticsearch cluster’s health and performance. Update mappings and settings as your data and query needs evolve.

Mind the indexing overhead:
Parent-child relationships introduce indexing overhead. Ensure that the benefits of your data model justify the additional indexing complexity.
Conclusion
Parent-child relationships offer a valuable tool for managing hierarchical data within Elasticsearch, providing benefits like:

Clear data structure:
Explicitly defines connections between documents, making relationships readily apparent.

Efficient navigation:
Enables hierarchical querying and filtering, simplifying exploration of data structures.

Joining capabilities:
Allows joining across parent and child levels for specific queries, offering insights into complex relationships.
However, it’s crucial to be aware of the limitations and trade-offs associated with parent-child relationships:
Performance:
Updates on parents can trigger cascading updates on children, potentially impacting performance.

Complex queries:
Joining across multiple levels of parents and children can be costly, leading to slower search times.

Flexibility:
Managing intricate relationships and ensuring data consistency requires careful planning and implementation.
In summary, parent-child relationships empower users to model hierarchical data structures in Elasticsearch while retaining the ability to search and aggregate across multiple levels. By predefining explicit connections between documents and employing specialized join queries, one can uncover insights from intricate relational datasets easily. However, careful planning is required to ensure proper mappings, optimized routing, and performant query execution. Alternatives like nesting or denormalization may sometimes prove more suitable depending on data and use case specifics.
Utilize this guide to make informed decisions about the parent-child approach, best optimize your implementation, and unlock transformative value from labyrinthine data relationships with Elasticsearch.

