Media Coverage
Media Coverage Press Release
Press ReleaseUnleashing the Power of Tableau for Big Data Analysis: Part One
Harnessing Big Data Insights with Tableau: A Comprehensive Guide
Mastering Big Data Analysis: Tableau’s Essential Tools and Techniques
I. Introduction to Big Data & Tableau
In this three-part series, we will provide an overview of the on-premises big data ecosystem and how it works with Tableau. We will also explore the Hadoop Ecosystem along with best practices for optimizing performance in Hadoop and Tableau.
Hadoop is an open-source framework supported by Cloudera that allows distributed processing of large datasets across a cluster of commodity computers. It is the industry leading technology in big data processing and storage. Relative to relational databases, writes are fast because of schema-on-read. It will accept whatever datatypes are written into the cluster. Raw, unprocessed data can be loaded into Hadoop with the structure imposed at processing time based on the requirements of the processing application. Despite the schema-less nature of Hadoop, the main consideration is the directory structure for data loaded into the Hadoop distributed file system (HDFS).
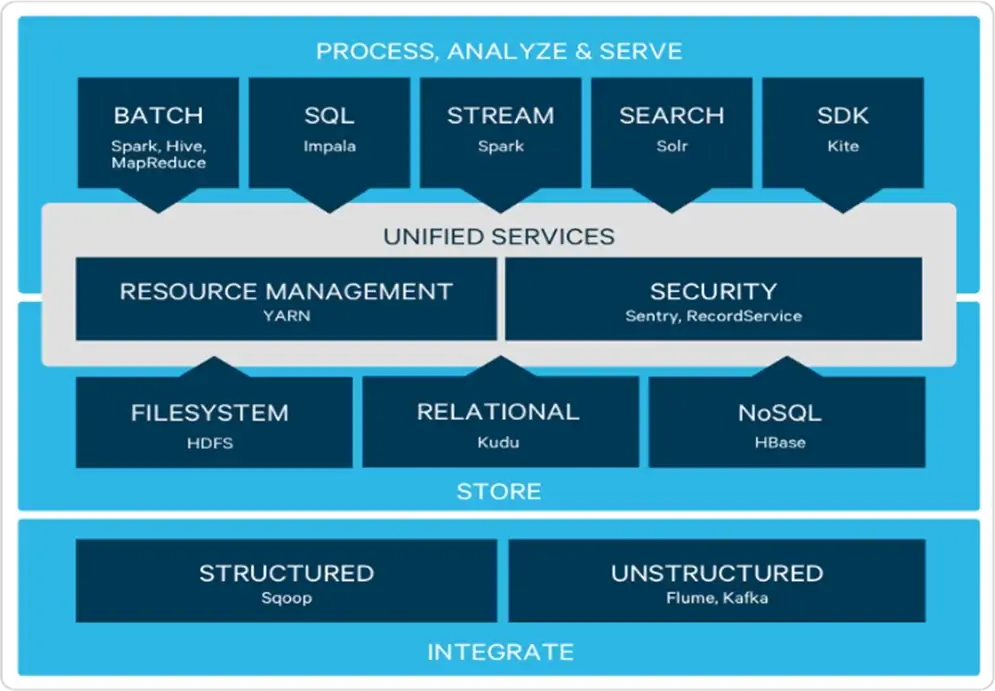
The components of Hadoop are the Hadoop Distributed File System (HDFS) for data storage, YARN for resource management, and MapReduce for data processing. Hadoop redundantly stores blocks (pieces of data) across servers. HDFS stores and manages data, while MapReduce processes and computes data in HDFS. MapReduce is a programming model that allows you to conduct computations on many machines and forces you to break your process into 3 stages. In the “Map” phase, documents are split and read across different nodes. In the “Shuffle” phase, outputs are assigned to different machines. In the “Reduce” phase, all the results from the map phase are combined.
Understanding the Role of Tableau in Big Data Analysis
Navigating Complex Datasets: Tips and Tricks for Effective Analysis
Leveraging Tableau’s Advanced Features for Big Data Exploration
Optimizing Performance: Best Practices for Analyzing Big Data with Tableau
Hadoop best practices include avoiding data storage in small files to preserve resources to run intensive Hadoop jobs. One HDFS block is 128MB, so you should try to keep this as your minimum threshold for your file size. In addition, it is recommended to store in ORC or Parquet Format. By storing data in ORC or Parquet format, the data is compressed for optimal storage and performance. Also, it’s preferable to avoid Small Partitions (less than 128 MB) to make sure Hadoop’s resources are used properly.
Tableau is a data visualization tool that allows end users to dynamically interact with their data to find patterns and trends. With Tableau you can ingest structured tabular data and perform interactive analysis by dragging and dropping columns into a canvas that presents your data in various shapes and colors. You can connect Tableau to text files and excel files along with various databases. Tableau has direct native connections to data in Hadoop, and therefore allows for dashboarding solutions facilitating big data analysis. In this series, we will leverage Impala as our data source. To view a short introductory video on how Tableau works, see https://www.tableau.com/products/desktop .
There are several considerations to keep in mind when designing views and dashboards. For example, you should err on the side of using calculations at the database level rather than in Tableau. Furthermore, it’s recommended that you minimize the number of records by utilizing extract filters to keep only the data you need. It’s also helpful to reserve the top left space of your dashboard for data you want users to notice the most. Lastly, limit the number of views and resist the urge to pack in too much information into one dashboard. When too many views are included in the dashboard, performance is compromised, and the user has more difficulty obtaining key insights.
Getting Started with Tableau: Setting Up Your Environment for Big Data Analysis
Exploring Data Sources: Connecting Tableau to Big Data Platforms
Visualizing Big Data: Creating Stunning Dashboards and Visualizations with Tableau
Advanced Analysis Techniques: Going Beyond the Basics with Tableau for Big Data
II. Installing Tableau
Go to the Tableau Desktop installation page: https://www.tableau.com/products/desktop/download
When you have finally downloaded and installed Tableau, fill out the registration form to activate your trial instance:
III. Connecting to Tables in Impala
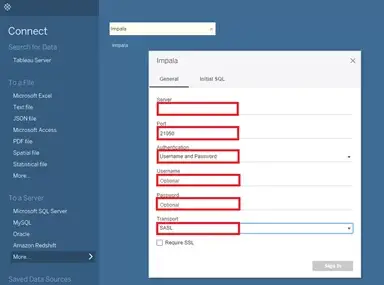
Connect to Impala on the Tableau home screen:
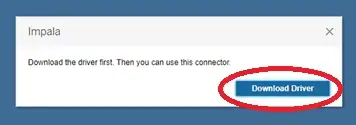
If the Impala driver is not already installed, you will get the prompt below. Otherwise, feel free to skip ahead to the connection details step. Click “Download Driver” and you will be redirected to a Tableau webpage with instructions on how to download drivers.:
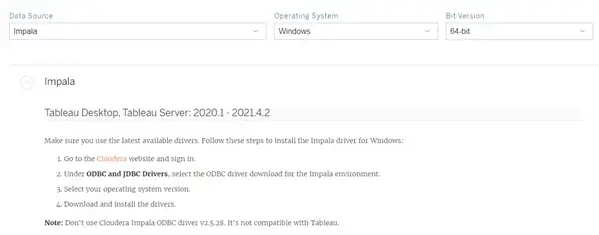
Click the link to the Cloudera website in the instructions below:
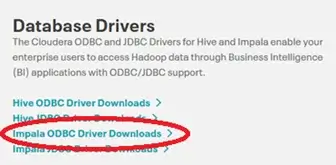
On the Cloudera page, scroll down to the section for Database Drivers. Click “Impala ODBC Driver Downloads”:
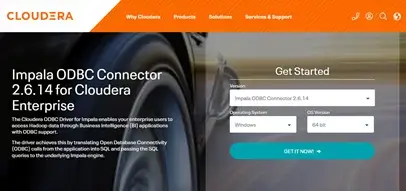
In the Cloudera download page for the ODBC Connector, enter the details for your computer (operating system and OS version) and click “Get it Now”:
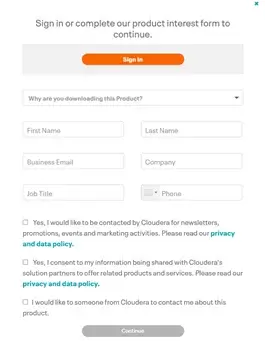
Enter your information to continue onto the next step:
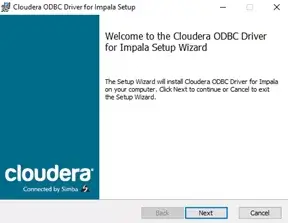
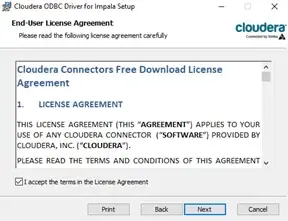
Accept the license agreement, download the driver, and follow the installation steps:
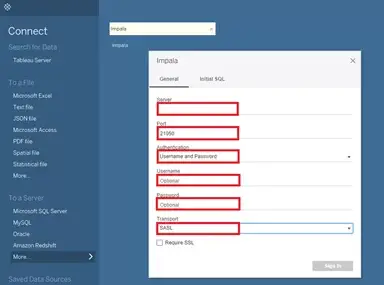
Return to Tableau Desktop and you will find the following options for Impala appearing. Enter connection details for Impala:
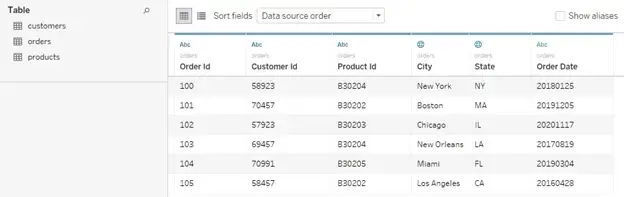
Once this step is completed, you’ll be able to see your Impala tables loaded on the left hand pane of the “Data Sources” tab in Tableau.