








 Media Coverage
Media Coverage Press Release
Press Release
Efficient end-to-end data pipelines are crucial for organizations to move, store, and transform data. Your very ability to access data and put it to good use depends on your data pipelines. In this blog, I will walk you through the process of creating a robust end-to-end data pipeline that seamlessly integrates Kaggle, AWS S3, and Snowflake, complete with automated email notifications. Whether you’re a data engineer, analyst, or technical professional, this guide should help you implement a production-ready data pipeline.
Streamlining Data Pipelines with Automation
Efficient Data Workflows: Kaggle to Snowflake Integration
Enhancing Data Operations with Notifications in Snowflake
Why Automate Data Pipelines?
Setting Up Kaggle to Snowflake Integration
Configuring Notifications for Data Workflows
Best Practices for Data Pipeline Automation
Preparing Kaggle Datasets for Automation
Snowflake Integration Tips and Tricks
Streamlining Data Monitoring with Notifications
Troubleshooting Common Issues in Data Pipeline Automation
Step-by-Step Process
Data Extraction
Step 1
Import Required Libraries
Import the necessary libraries in a Python environment to facilitate data extraction and handling.

Step 2
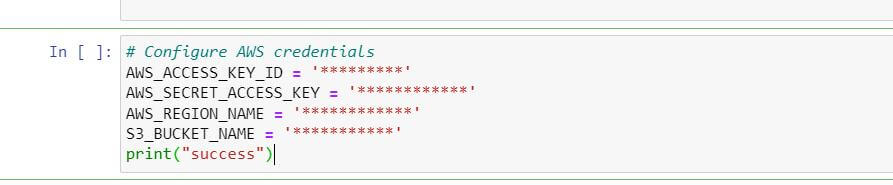
Configure AWS Credentials
Collect AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY from your AWS account. Specify details such as the S3 bucket where files will be uploaded.
Step 3
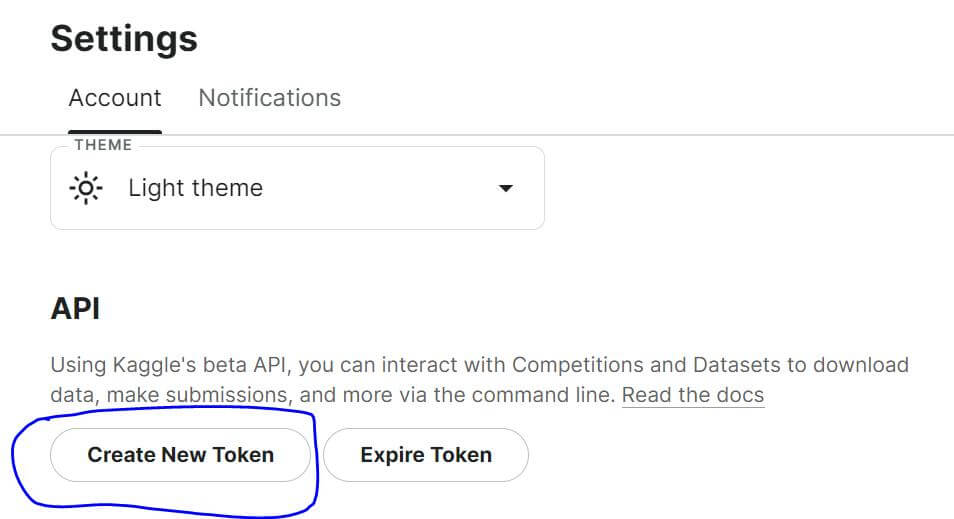
Configure Kaggle API
Obtain your Kaggle API token from Kaggle account settings (Settings -> API -> Create New Token). Download the JSON file containing your API key copy that key and paste it into the code.
Step 4
Authenticate with Kaggle API
Use your Kaggle username and API key to authenticate and establish a connection with the Kaggle API.

Step 5
Download Dataset
Provide the dataset link or identifier to download the dataset from Kaggle to a specified location or path on your system.
Note: For example,here we’ll use a retail-orders dataset to demonstrate the process. We can paste any link from Kaggle.

Data Loading
Step 1
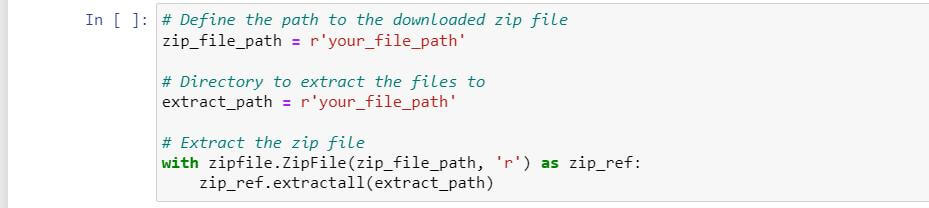
Extract Zipped File
Unzip the downloaded dataset file to access its contents.
Step 2
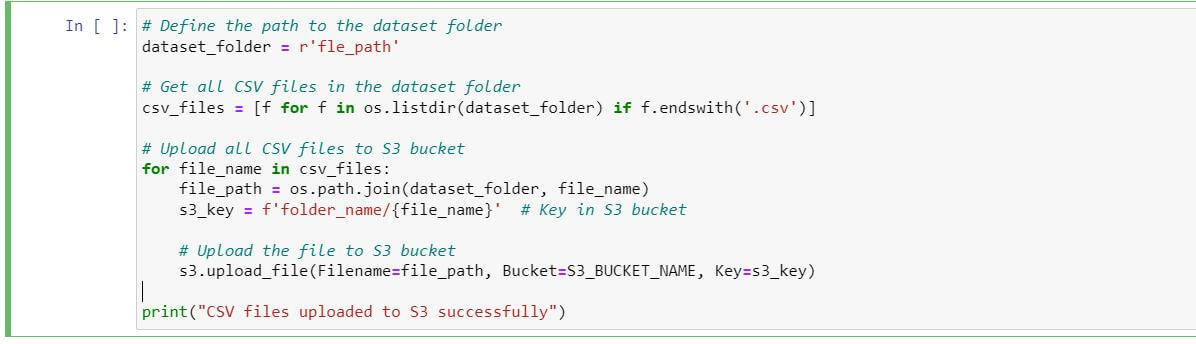
Upload to S3 Bucket
Upload the extracted files to the specified Amazon S3 bucket for storage and accessibility.
Data Integration (Snowflake)
Set up a storage integration in Snowflake to connect to your AWS S3 bucket.
Load the batch-wise data using Snowpipe.
Step 1
Creating Storage integration
create or replace storage integration Test
type = external_stage
storage_provider = s3
storage_aws_role_arn = 'arn:example'
enabled = true
storage_allowed_locations = ( "s3:path")
comment = 'integration with AWS s3 bucket';Step 2
Stage Creation
CREATE OR REPLACE STAGE capstoneprac
URL = 's3 path'
STORAGE_INTEGRATION = Test ;Step 3
Checking the stage to determine whether data is loaded or not
list@capstoneprac;Step 4
Creating Table
create table orders_data(
Order_Id int,
Order_Date date,
Ship_Mode varchar(250),
Segment varchar(250),
Country varchar(250),
City varchar(250),
State varchar(250),
Postal_Code int,
Region varchar(250),
Category varchar(250),
Sub_Category varchar(250),
Product_Id varchar(250),
cost_price int,
List_Price int,
Quantity int,
Discount_Percent int);Step 5
File format creation
CREATE OR REPLACE file format Test type = csv field_delimiter = ',' skip_header = 1 FIELD_OPTIONALLY_ENCLOSED_BY='"', empty_field_as_null = TRUE;Step 6
Continous data loading using Snowpipe
CREATE or replace PIPE Test
AUTO_INGEST = TRUE
AS
COPY INTO table_name
FROM @stage_name
FILE_FORMAT = Test;Step 7
Checking pipe status and collecting ARN
Describe pipe Test;
select system$pipe_status('Test);Step 8
Copy the ARN from the desc pipe and paste it into the Event notification
Step 9
Checking data in the table
select * from orders_data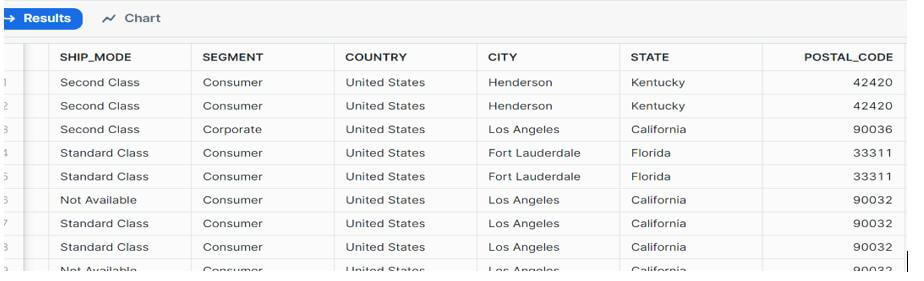
Using Snowflake Metadata for Logs
- Snowflake’s information schema (Information Schema) contains views and tables that provide metadata about objects and operations within the Snowflake account.
- Now implement a stored procedure in Snowflake to dynamically capture and log changes in table row counts and Snowpipe statuses within the schema. It ensures efficient tracking and logging of relevant database activities, monitoring, and audit purposes within the Snowflake environment.For example:

Email Notification Triggering
Implement automated email notifications triggered by changes in Snowflake tables, ensuring users are promptly informed of updates and changes.
Step 1
Import Required Libraries
Import the necessary libraries in a Python
import snowflake.connector
import smtplib, ssl
from email. mime.multipart import MIMEMultipart
from email. Mime.text import MIMETextIntroduction
1. SMTP, SSL: The smptlib is an inbuilt Python library that allows us to send emails using SMTP (Simple Mail Transfer Protocol) for sending emails. It connects to the SMTP server (smtp.gmail.com in this case) using the SSL/TLS secured port (465), and SSL (Secure Sockets Layer) helps for a secure connection.
2. MIME (Multipurpose Internet Mail Extensions): MIME is a standard that extends the format of email messages to support various types of content beyond simple text. It allows emails to include multimedia content such as images, audio, video, and attachments and enables formatting of messages in plain text and HTML.
3. Before writing a Python code we need to make some changes in our Gmail account (sender’s Gmail account)-
- Go to your Gmail account -> Security -> Enable 2-step verification
- Gmail account -> Security -> App Passwords -> Select the app and device you want to generate the app password for -> In select app choose other and give a custom name as python -> click on generate (this generates a password which we can use in our python code for logging in).
- Note- This is not required in real-time.
Step 2
Connection to Snowflake
Establishing a connection to Snowflake involves providing various authentication details such as username, password, warehouse, database, schema, and role details to connect.

Step 3
Setting email preferences
For the mail body, we can use the HTML format and define it as per our requirements.
For example, here we are using Python function to define the email body, subject, etc., to send the email.
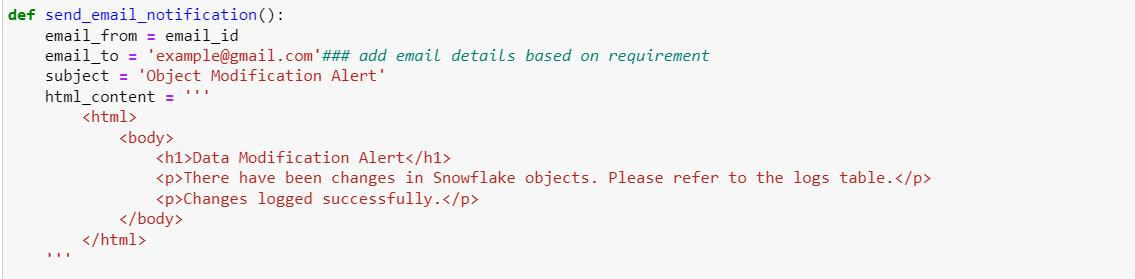
Step 4
Executing and printing result
We are executing the required query or statement here.
Step 5
Closing Connection
After completing all the above processes, we must close the connection.

Step 6
Finally, the email notification is triggered to specified mail.
By implementing this pipeline, organizations can efficiently manage their data journey from extraction through Kaggle, storage in AWS S3, processing in Snowflake, and automated notifications via email. The solution is scalable, maintainable, and can be adapted to meet various business needs. Remember to follow security best practices when handling credentials and consider implementing monitoring and error handling for production environments.
