








 Media Coverage
Media Coverage Press Release
Press ReleaseSimplifying Semi-Structured Data Management with Snowflake
Unlocking Efficiency: Best Practices for Snowflake Data Vault 2.0
Seamlessly Storing and Retrieving Semi-Structured Data: Snowflake Strategies
Introduction:
In current days technology advancement, high volumes of data are captured for a variety of needs. We are heavily dependent on data for making simple to crucial decisions in our day-to-day activities like navigation, finding a good medical facility, shopping etc. to have a hassle-free experience, whilst large scale businesses across the sectors, government bodies, educational institutions, healthcare (and the list goes on and on) etc., are heavily banking on the data to successfully run their own systems and to compete with others. As someone rightly said that data is the new fuel in the present scenario.
Data is highly categorized into 3 formats Structured, Semi Structed and Unstructured data.
- Structured Data: Data that is cleansed, organized, fits into pre-defined schema and easily readable, for ex. names, dates, addresses, credit card numbers, stock information, geolocation, and more. Structured data is usually stored in a tabular format in a variety of ways like SQL Databases, Excel sheets or in a simple notepad
- Semi Structured Data: Data that doesn’t have a rigid schema and is organized as internal semantic tags or metadata or markings that enables analysis. Data is organized in a hierarchy of tags having parent child relationship, metadata or other markers which helps in retrieving the data to create records and fields. A few examples of semi-structured data sources are emails, XML, JSON, HTML and other markup languages, binary executables, TCP/IP packets, zipped files, and web pages
- Unstructured Data: Unstructured data is the information that cannot be arranged in a specific schema or data model and cannot be stored in RDBMS systems. It has its own internal format but doesn’t confine to a specific format that can be easily stored as rows and columns in a relational database or a flat file. Structured and semi structured data can be easily transformed and stored into RDBMS systems, but unstructured data is a data flow from heterogenous systems collected at one place.
- Examples of unstructured data are:
- Rich media. Media and entertainment data, surveillance data, geo-spatial data, audio, weather data
- Document collections. Invoices, records, emails, productivity applications
- Internet of Things (IoT). Sensor data, ticker data
- Analytics. Machine Learning, Artificial Intelligence (AI)
- Examples of unstructured data are:
Objective:
The objective of this write up is to introduce efficient ways to store and retrieve semi structured data using the most popular on cloud datawarehouse platform Snowflake and the emerging data modelling methodology Data Vault 2.0. We’ll be discussing storing and retrieval of data from JSON files in precise, similar techniques can be applied to other mark up languages.
Understanding Snowflake Data Vault 2.0: A Comprehensive Guide
Best Practices for Managing Semi-Structured Data in Snowflake
Strategies for Efficient Data Retrieval in Snowflake
Tips for Optimizing Snowflake Data Storage and Retrieval
Exploring Semi-Structured Data Handling in Snowflake
Practical Tips for Snowflake Data Vault 2.0 Implementation
Streamlining Data Retrieval Processes in Snowflake
Maximizing Efficiency with Snowflake Data Storage Solutions
What is Snowflake?
Snowflake is a fully managed SaaS (software as a service) offering that provides a single platform for data warehousing, data lakes, data engineering, data science, data application development, and secure sharing and consumption of real-time / shared data. Snowflake enables data storage, processing, and analytic solutions that are faster, easier to use, and far more flexible than traditional offerings.
The Snowflake data platform is not built on any existing database technology or “big data” software platforms such as Hadoop. Instead, Snowflake combines a completely new SQL query engine with an innovative architecture natively designed for the cloud. To the user, Snowflake provides all the functionality of an enterprise analytic database, along with many additional special features and unique capabilities.
The Snowflake Architecture comprises of
References: https://docs.snowflake.com/en/user-guide/intro-key-concepts.html
What is Data Vault 2.0?
Data Vault 2.0 is a system of business Intelligence that represents a major evolution in the already successful Data Vault architecture. It has been extended beyond the Data Warehouse component to include a model capable of dealing with cross-platform data persistence, multi latency, multi structured data, and massively parallel platforms. It also includes an agile methodology called Disciplined Agile Deliveries (DAD) within it, which is both automation and load friendly. The methodology brings best practices and high-quality standards that can easily be automated.
The Data Vault Model (when built properly) is integrated by Business Keys. These business keys are the unique identifiers for core business concepts. It is recommended to base the raw Data Vault model on a business taxonomy, where concept terms are defined to have meant horizontally across the business. The model has 3 main core components the Hubs, Links and Satellites as depicted in the below diagram.
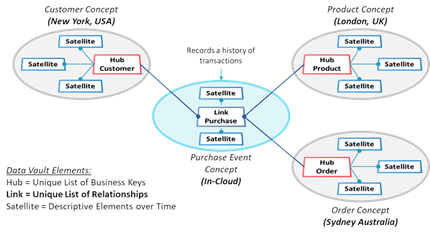
References: https://datavaultalliance.com/data-vault-2-the-details/
What is JSON?
JavaScript Object Notation (JSON) is a standard text-based format for representing structured data based on JavaScript object syntax. It is commonly used for transmitting data in web applications (e.g., sending some data from the server to the client, so it can be displayed on a web page, or vice versa).
Sample JSON file snippets:
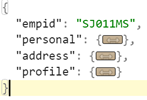
Above structure consists of a simple employee record with empid, personal information, address, and employee profile description, there are 3 main tags personal, address and profile which consists of fields with relevant information.

Data extracted from the above JSON and stored in a relational format is depicted below.
| Emp Id | Name | Gender | Age | Street Address | City | State | Postal Code | Designation | Department |
| SJ011MS | Smith Jones | Male | 28 | 724th Street | New York | NY | 10038 | Deputy General | Finance |
Challenges of storing semi structured data:
The example mentioned above is a simple and straight forward structure which comprises of just one record, but in real time projects we may get files having huge volumes of data with much more complex structures. JSON files are result of API calls in real time projects or the files maybe generated by upstream systems and send in a batch to get loaded into the warehouse. The schema may change anytime and there may be additions or deletions of certain fields within a tag or altogether a new set of tags. A slight variation of the above example could be.


Where Address is an array that contains the list of employee addresses (primary, secondary etc.) and the relational schema for loading the above data changes as depicted below.
| EmpId | SJ011MS |
| Name | Smith Jones |
| Gender | Male |
| Age | 28 |
| StreetAddress1 | 724th Street |
| City1 | New York |
| State1 | NY |
| PostalCode1 | 10038 |
| StreetAddress2 | 724th Street |
| City2 | New Jersy |
| State2 | NJ |
| PostalCode2 | 10083 |
| Designation | Deputy General |
| Department | Finance |
We may get additional data for the same employee whenever it gets added in the source system. As shown in the example below, skills of the employee are added and may come as incremental data in real time projects.

The relational schema changes again
| EmpId | SJ011MS | StreetAddress2 | 724th Street |
| Name | Smith Jones | City2 | New Jersy |
| Gender | Male | State2 | NJ |
| Age | 28 | PostalCode2 | 10083 |
| StreetAddress1 | 724th Street | Designation | Deputy General |
| City1 | New York | Department | Finance |
| State1 | NY | Database_Skills | Oracle, Snowflake |
| PostalCode1 | 10038 | Visualization_Skills | Tableau, Power BI |
The challenge lies in changing the relational schema as and when additional information is getting added or it gets deleted, prior intimation of schema change may not be possible when the JSON pull is dynamic using web API calls. This scenario can be handled effectively by modelling the data store in Snowflake using Data Vault 2.0 methodology.
Agility of Data Vault 2.0:
The core layer of Davault 2.0 architecture comprises of Raw Vault, Business Vault, and Information mart. Raw Vault houses raw data straight form the source with out any business rules applied on it, entire change history from the source is maintained in Raw Vault. Business Vault contains sparsely selected data from Raw Vault with business rules applied on it (i.e., transformed data) and finally Information mart consists of data marts, all the objects here are views created by mixing and merging the objects from Raw and Business Vaults.
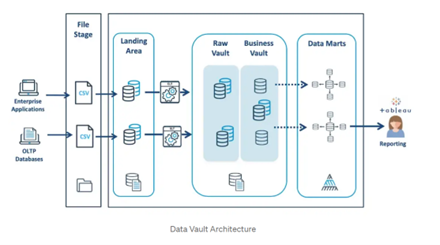
Architecture Reference: https://medium.com/@jryan999/data-vault-an-overview-27bed8a1bf9f
Data Vault 2.0 is built to support Agile/Scrum methods of project development, we can start building the warehouse even before we have a detailed spec of business requirements. It all starts with housing the source data into the raw vault. While the data modellers work closely with source SMEs to design the raw vault, the ETL, QA teams work in tandem to build data pipelines and testing as soon as the new objects are created in the raw vault, at the same time, the business analysts can work closely with the stake holders on the business requirements for data presentation. The interdependency between the teams is bare minimum and the entire project plan smoothly fits into Agile/Scrum way of development in sprints.
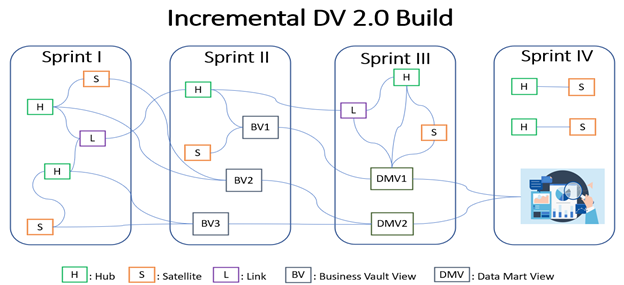
Since the Business Vault and Data Mart objects are views built on Raw Vault we can scrap and re-built them anytime in case of changes in business requirements, the effort of re-design is minimum when compared to traditional architectures.
Let’s look at some of the simple and straight forward use cases for Raw Vault design by taking the above discussed Employee JSON example as yardstick.
Use Case I: When we don’t have any specific business requirements for data consumption and Employee data is getting pushed from source as JSON files, while the schema definition tends to change anytime and the latest snapshot holds good for analysis.
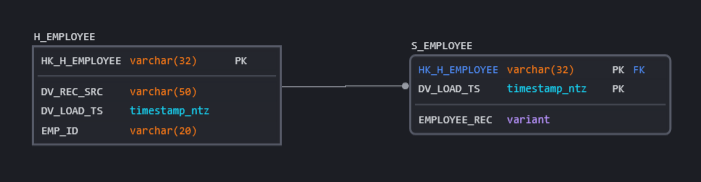
The Hub holds the Unique business key for identifying a single employee (here it is EMP_ID), and the satellite stores each individual record as a parsed JSON in the EMPLOYEE_REC field, each time an updated record comes, it gets loaded into the satellite with the latest timestamp stamped on it which helps in fetching the latest updated record when sorted on the DV_LOAD_TS whilst maintaining the change history.
Use Case II: When there’s a clear direction on the fields required for data analysis and the tags associated with them and few additions/changes to the schema in near future are expected.
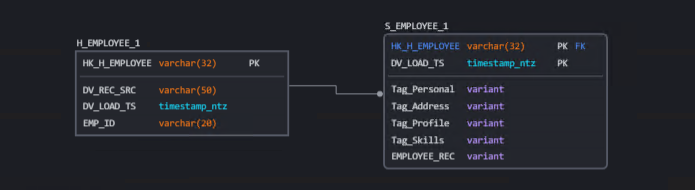
The Hub stores information same as Use Case I, and the satellite contains fields one for each tag required for pulling the necessary columns for analysis as parsed JSON. The entire record is also stored as parsed JSON in a Separate filed for pulling any additional information. This design helps in keeping the ETL code simple and straight forward and enhances performance of the query when dealing with data sets with large volumes of data.
Use Case III: This is specific to snowflake and another variation of Use Case II, where some of the primary tags are coming as empty on some days and with information on other days, in this scenario the JSON parsing functions skips the entire record when you try to pull information from the empty tags with field references.
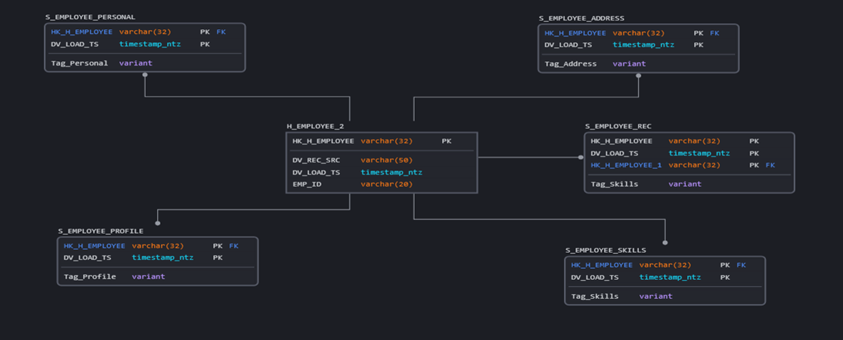
The Snowflake Advantage:
Following are the few main features of Snowflake which makes it unique among the cloud Datawarehouse offerings.
- Can be hosted on any of the major cloud platforms AWS, Azure, GCP
- High performance MPP Query Engine and Columnar storage
- Automatically Scalable
- Zero Administration
- Storage and support for structured and semi structured data (High Performance queries especially on JSON data structures)
- Seamless data sharing
- Availability & Security
- Micro Partitions and Data Clustering
- Supports Python scripting for Data Science, AI/ML
Snowflake provides rich set of functions for transforming and querying the data on the fly with execution times ranging from milliseconds to seconds. Snowflake offers some of the special data types like Variant, Object, Array for storing semi structured data (JSON, XML etc.), key-value pairs, objects, and arrays. It Automatically splits the data, sorts, and stores it in micro partitions which results in high query performance.
Let’s revisit Use Case I discussed above and understand how the data loaded into snowflake appears.
H_EMPLOYEE:

S_EMPLOYEE:

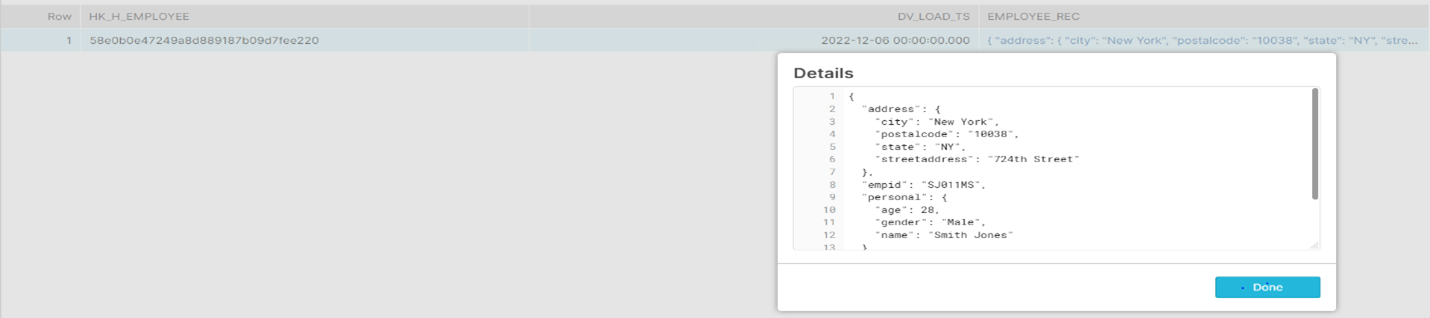
Entire employee record is stored as parsed JSON in EMPLOYEE_REC field that is defined as variant datatype.
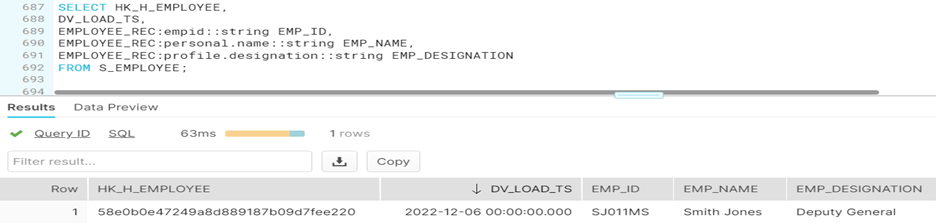
Data retrieval is simple and straight forward.
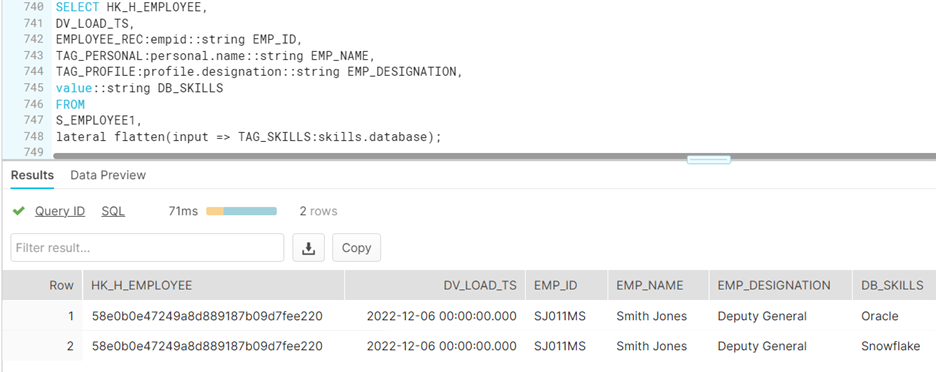
Let’s revisit Use Case II discussed above and understand how the data loaded into snowflake appears.
H_EMPLOYEE1:

S_EMPLOYEE1:

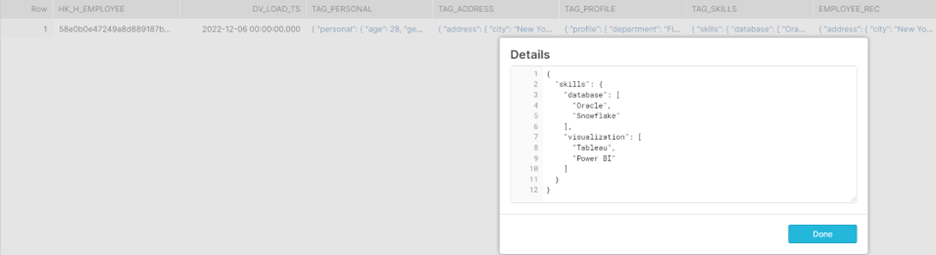
Parsing an Array nested in JSON tags.
Conclusion:
Whatever we discussed so far in this write up is just “a tip of the iceberg”, we encounter plethora of complex use cases when dealing with semi structured data in real time. When you have deep understanding of the data structures coupled with a data modelling methodology like DV2.0 and powerful database platforms like Snowflake, even the herculean task becomes simple.
To Know More About Data Vault Visit:
https://datavaultalliance.com/
To Know More About Snowflake Visit:
