








 Media Coverage
Media Coverage Press Release
Press ReleaseComparing Amazon S3 and HDFS: A Comprehensive Guide
Understanding the Differences Between S3 and HDFS for Big Data Storage
Choosing the Right Data Storage Solution: S3 vs HDFS
How is big data stored in the cloud?
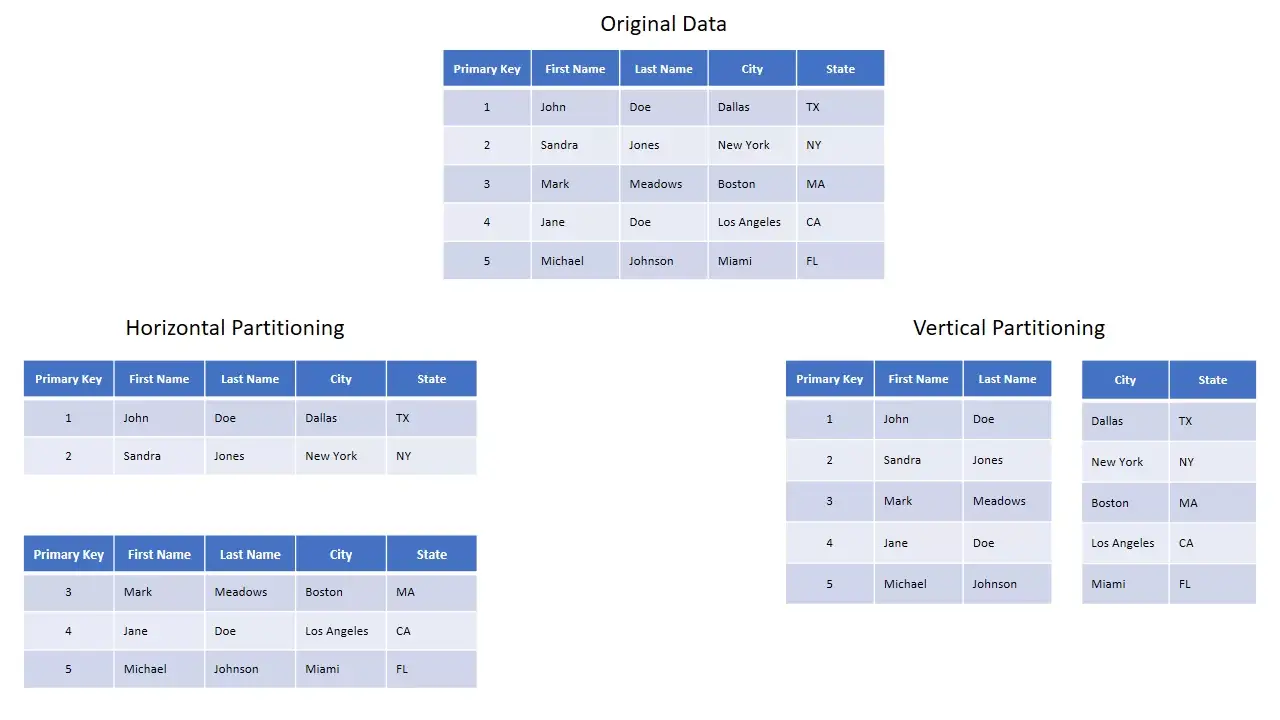
For the better part of the last decade, Hadoop has served as the industry standard mechanism for storing big data with HDFS acting as its core architectural achievement. Although Hadoop has dominated market share of big data storage, cloud technologies have emerged as a viable alternative to on-premises data storage. A cloud technology that offers a similar use case as Hadoop is AWS’s S3 storage solution. If you are using Amazon’s cloud computing infrastructure in big data projects, S3 is an ideal fit. However, there are several differences between Hadoop and S3. S3 is an object store, and therefore is not strictly used as a file system. S3 accesses and stores objects using the key/object relationship. S3 also uses an eventually consistent model, similar to what you would find with NoSQL storage design. Instead of partitioning and bucketing, S3 employs data sharding*, which allows you to split and store a single dataset
*Sharding can result in vertical or horizontal logical shards/partitions (see below)
Introduction to Amazon S3 and HDFS
Key Features and Capabilities of Amazon S3
Exploring Hadoop Distributed File System (HDFS)
Comparing Performance, Scalability, and Cost of S3 and HDFS
Considerations when deciding between S3 and Hadoop
Scalability
S3 allows you to de-couple your computing infrastructure from your storage needs. You can store all your data in S3 and you don’t have to monitor your storage. You can easily scale up and add nodes to your cluster in the cloud. With HDFS, increasing storage space requires larger hard drives to already existing nodes or simply adding more nodes to the cluster. However, this process is slow and expensive.
Cost
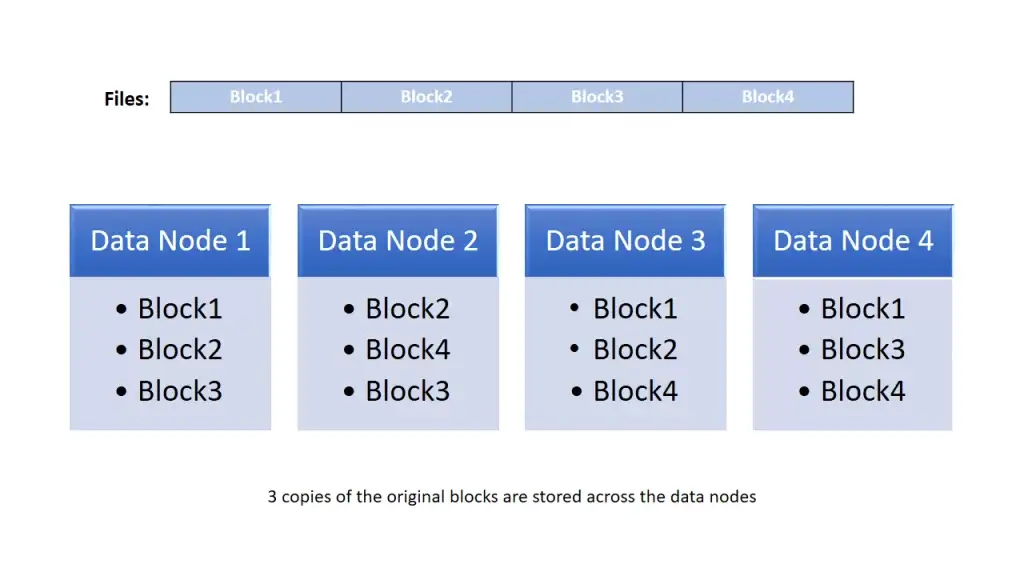
If you can easily predict your storage needs and can assume that they will remain stable, an on-premises solution such as Hadoop could be more cost effective. However, as a company’s storage and computing needs evolve, S3 becomes far more cost effective due to its ability to auto-scale. Furthermore, there’s a significant labor cost savings with opting for S3. While it may take a team of Hadoop engineers to maintain HDFS, S3 requires much less active maintenance. From an architectural standpoint, HDFS also automatically creates 3 copies* of each block of data. This means that storage costs account for triple the storage necessary for the baseline data. With S3, AWS backs up the data automatically and the customer only pays for the data that needs to be stored instead of its replicas.
*When storing data in HDFS, you must budget for 3x the storage space that your data occupies.
Overview of Amazon S3: Features, Use Cases, and Benefits
Understanding HDFS Architecture and Functionality
Performance Comparison: S3 vs HDFS
Cost Analysis: S3 vs HDFS for Big Data Storage
Availability
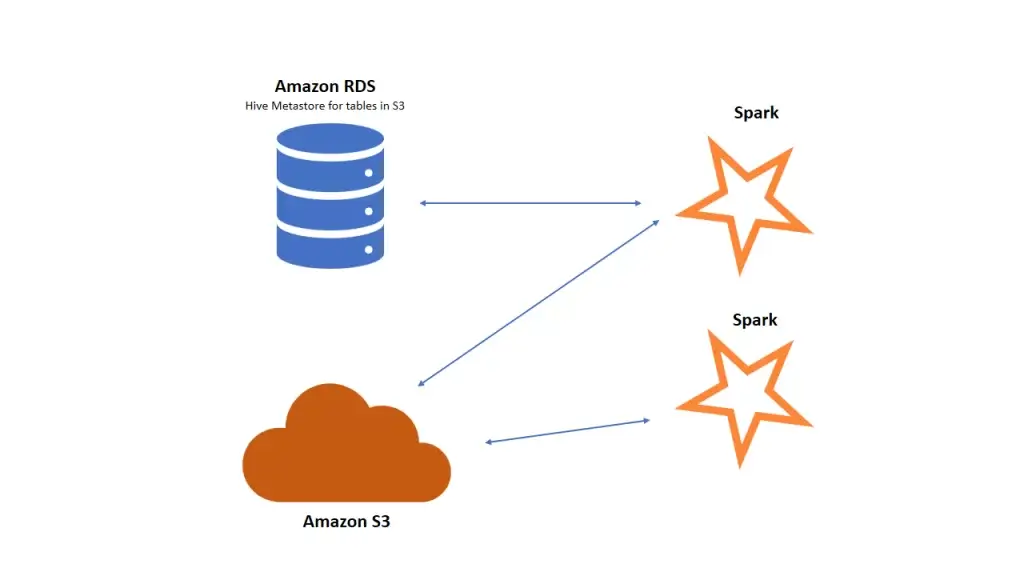
AWS S3 offers an extremely durable infrastructure that is 99.99999999999% available (eleven nines), meaning that big data storage in S3 has significantly less downtime. HDFS has a significant advantage with read and write performance due to data locality. HDFS can provide many times more read throughput than S3, but this issue is mitigated by the fact that S3 allows you to separate storage and compute capacity. As a result, AWS gives you the ability to expand the cluster size to address issues with insufficient throughput. However, if you decide to use Spark* as your analytics engine to access data and block size to facilitate parallelism, you will find that latency issues are easily resolved as well.
*Spark can operate on top of S3 with RDS serving as a Hive metastore for the data
Operational Considerations
S3 provides seamless fault tolerance with its ability to provide replication of data across regions. S3 also provides many ways to encrypt data to meet security needs that are often required by regulators within specific sectors. Nevertheless, Hadoop provides several options for data security, including kerberized user authentication and file system permission layers.
Both HDFS and S3 have some key limitations as well. For example, HDFS doesn’t do a particularly good job of storing small files. An oversupply of small files will overload the name node with metadata and impact performance. In addition, data stored on one cluster is not available on a different cluster. In S3, however, you can spin up multiple clusters simultaneously. The main limitations associated with S3 are with maximum file size being set to 5 gigabytes and the unavailability of storage formats such as Parquet and ORC.
Will Cloud Supplant HDFS?
Given many of the enhancements cloud big data storage provides, it’s highly likely that cloud technologies such as S3 will continue to eat at the market share HDFS has established. Nevertheless, there will always be use cases for on-prem storage solutions and they will remain an integral part of the Big Data ecosystem. What will likely emerge are hybrid solutions that incorporate both cloud and on-prem technologies. If you have a particularly large cluster, you can use S3 to store older and infrequently processed data while keeping more frequently used data on-premises with Hadoop. You would be able to pull data from S3 using DISCP or you could migrate data between environments using Spark. Given this evolution in the big data ecosystem, it is difficult to imagine how the on-premises model of big data storage will maintain the dominance it has had over the market over the better part of the past decade.