








 Media Coverage
Media Coverage Press Release
Press ReleaseStrategies for Optimizing Ad-Hoc Querying with AWS
Accelerating Insights: Ad-Hoc Querying with AWS
In data management, the journey from raw data to actionable insights involves several stages, with Data Warehouse and Data Lakehouse standing as pivotal destinations. The process typically commences with data ingestion into staging areas, where the initial cleaning and validation occur. The duration for moving data from staging to a Data Warehouse or Lakehouse can vary based on volume and complexity, ranging from hours to days. ETL (Extract, Transform, Load) pipelines play a crucial role in this transition, orchestrating the seamless movement of data while ensuring its integrity. These pipelines streamline the transformation of raw data into a structured and optimized format, readying it for analysis and reporting in the subsequent stages of the data journey.

When it comes to data movement within ETL (Extract, Transform, Load) processes, a staging layer emerges as a silent yet indispensable element. Acting as an intermediary repository, the staging layer is pivotal for ensuring data integrity, facilitating intricate transformations, and optimizing performance. Its primary role lies in shielding the source and target systems from the potential disruptions that may arise during the transformation and loading phases. Commonly used staging layers include file systems, both local and network-based, providing a straightforward yet effective solution. Database staging layers, whether relational or NoSQL, offer the advantage of SQL-based transformations. However, increasingly, cloud-based storage solutions like Amazon S3 are gaining prominence due to their scalability, durability, and seamless integration with modern ETL/ELT tools.
Renowned for its scalability, S3 transcends traditional storage limitations, accommodating vast amounts of data effortlessly. Its 99.999999999% durability reassures users of a highly reliable staging environment, and its pay-as-you-go pricing model ensures cost-effectiveness. What sets S3 apart is its integration prowess within the expansive AWS ecosystem, fostering seamless connections with various data processing and analytics tools. S3’s robust security features, including access controls, encryption, and audit logging, fortify data confidentiality and integrity. In essence, using AWS S3 as a staging layer not only streamlines the ETL process but also opens doors to a flexible, secure, and cost-efficient paradigm in the dynamic landscape of data management.
Understanding the Challenges of Ad-Hoc Querying
Leveraging AWS Services for Faster Insights
Best Practices for Efficient Ad-Hoc Querying
Choosing the Right AWS Services for Ad-Hoc Querying
Implementing Performance Tuning Techniques
Streamlining Workflow for Quick Time to Value
Challenges in Ad-Hoc Querying
While ad-hoc querying empowers analysts with the flexibility to explore data on the fly, it comes with its share of challenges that organizations must navigate to harness its full potential. One significant hurdle is the potential strain on system resources, especially in case of large datasets. Ad-hoc queries, by nature, can be unpredictable, leading to varying resource demands and performance issues. In scenarios where the user base and data volume tend to grow rapidly, scalability becomes paramount.
Another challenge lies in balancing speed and security. Ad-hoc querying often requires quick responses, but implementing stringent security measures can introduce latency. Striking a delicate balance between providing rapid access to data and ensuring robust security measures, including access controls and encryption, is crucial. Additionally, managing metadata and query history poses a challenge, as the diverse and exploratory nature of ad-hoc queries can result in a vast array of query logs and metadata that need effective organization and governance.
AWS Athena for Ad-hoc Querying
Amazon Athena is a powerful solution for conducting ad-hoc querying on data residing in the staging layer within AWS. Leveraging Athena’s serverless architecture, users can seamlessly explore and analyze data stored in Amazon S3 through intuitive SQL queries. This proves particularly advantageous in the context of the staging layer, where the need for flexibility and rapid exploration is key. By defining external tables in Athena that reference the data in the S3-based staging layer, users can efficiently execute ad-hoc queries without the need for complex infrastructure management. Athena’s compatibility with various data formats and its ability to handle massive datasets make it well-suited for the dynamic nature of the staging layer, allowing users to gain insights, validate data integrity, and perform necessary transformations on the fly. Additionally, Athena’s integration with AWS Identity and Access Management (IAM) ensures secure and controlled access, addressing concerns related to data governance and privacy within the ad-hoc querying process. Overall, AWS Athena provides a streamlined and powerful solution for unlocking the potential of ad-hoc querying within the staging layer, enabling data analysts and engineers to derive meaningful insights rapidly and efficiently.
Here’s how to set it up:
Step 1:
Set Up Permissions
Make sure you have the necessary permissions to create and manage Athena resources. Ensure that your AWS Identity and Access Management (IAM) user or role has the required permissions, such as AmazonAthenaFullAccess or custom permissions for Athena.
Step 2:
Open Athena Console
- Go to the AWS Management Console.
- Navigate to the Athena service under the “Analytics” section.
Step 3:
Create a Database
- In the Athena console, click on the “Query Editor” on the left sidebar.
- In the query editor, you can use the CREATE DATABASE statement to create a new database. For example:
CREATE DATABASE mydatabase;Replace “mydatabase” with your preferred database name.
Step 4:
Create a Table
After creating the database, use the CREATE TABLE statement to define a schema for your data. Ensure that your data is organized in a specific format, like CSV or Parquet, and is stored in a location on Amazon S3.
CREATE EXTERNAL TABLE mytable (
column1 datatype1,
column2 datatype2,
...
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION 's3://your-s3-bucket/path/to/data/'; Replace “mytable” with your preferred table name and adjust the column names and data types accordingly. Update the LOCATION parameter with the S3 path to your data.
Step 5:
Run Queries
Once your database and table are set up, you can start running SQL queries in the Athena console.
For example:
SELECT * FROM mydatabase.mytable WHERE column1 = 'some_value';Replace “mydatabase” and “mytable” with your database and table names.
Step 6:
View Query Results
Query results will be displayed in the Results tab of the Athena console. You can also save query results to a new table or export them to a CSV file.
AWS Glue Crawlers and Integration with Tableau
Glue Crawlers, a powerful feature within Amazon Web Services (AWS) Glue, play a pivotal role in automating schema inference for data stored in Amazon S3. As an integral part of AWS’s data preparation and ETL service, Glue Crawlers intelligently analyze the underlying structure of diverse datasets, providing a dynamic and automated approach to schema discovery. By harnessing the capabilities of Glue Crawlers, organizations can save valuable time and resources that would otherwise be spent manually defining schemas, ensuring data accuracy, and facilitating smoother downstream processing.
Once Glue Crawlers have seamlessly inferred the schema of your data in S3, the integration possibilities with AWS Athena and Tableau are nothing short of transformative. The Glue Catalog, a centralized metadata repository, enables easy accessibility and discovery of the inferred schemas. AWS Athena, a serverless query service, can then effortlessly interact with the Glue Catalog, allowing users to query data directly in S3 using standard SQL. This streamlined process empowers data analysts and scientists to gain valuable insights without the need for complex infrastructure management. Furthermore, the Glue Catalog serves as a bridge to Tableau, a leading data visualization platform, facilitating the creation of dynamic and interactive visualizations with the click of a button. This trifecta of Glue Crawlers, AWS Athena, and Tableau epitomizes the synergy achievable in modern data management, fostering agility, accuracy, and insightful decision-making for businesses embracing the power of AWS.
Securing the Data on S3
AWS offers a comprehensive suite of security features and encryption options to safeguard data stored in S3. With robust access control mechanisms, encryption capabilities, and innovative solutions like S3 Object Lambda endpoints, organizations can fortify their data protection strategies. Here are key considerations for securing data on S3:
- Leveraging AWS Data Lake, organizations can implement role-based access control (RBAC) and column-level access control for AWS Athena queries. This ensures that only authorized users have access to specific datasets and columns within those datasets, enhancing data governance and compliance.
- AWS provides various encryption options for data at rest and in transit on S3, including server-side encryption with Amazon S3-managed keys (SSE-S3), AWS Key Management Service (KMS), or customer-provided keys (SSE-C). Additionally, client-side encryption using AWS SDKs or AWS Key Management Service can be employed for an added layer of security.
- S3 Object Lambda endpoints enable dynamic transformation of data retrieved from S3 objects before it is returned to the requester. This functionality can be leveraged for redacting personally identifiable information (PII) from data objects in real-time, mitigating privacy risks and ensuring compliance with data protection regulations.
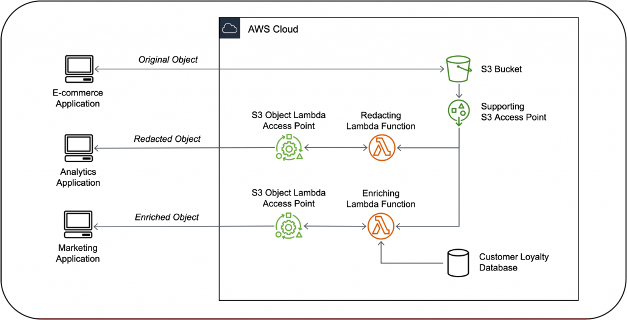
- With S3 Object Lambda, organizations can transform S3 objects in-flight as they are being retrieved through a standard Amazon S3 GET request by using S3 Object Lambda Access Points. AWS has provided two new pre-built AWS Lambda functions to help you detect, redact, and govern PII. Both functions are now available on the AWS Serverless Application Repository to be deployed at no license cost:
- The ComprehendPiiRedactionS3ObjectLambda function provides configurable redaction and masking of sensitive PII data.
- The ComprehendPiiAccessControlS3ObjectLambda checks if an object contains specified types of PII information and prevents retrieval to avoid inadvertent leakage of PII.
- AWS Athena seamlessly integrates with S3 Object Lambda, enabling organizations to execute SQL queries directly on transformed data served by S3 Object Lambda endpoints. This integration streamlines data processing workflows, allowing for real-time data transformations and redactions while querying data with Athena, enhancing both security and query performance.
Conclusion
In conclusion, the dynamic trio of AWS S3, Glue Crawlers, and Athena empowers organizations to unlock the true potential of ad-hoc querying within their data lakes. This powerful combination fosters a data-driven culture by facilitating rapid exploration, efficient transformations, and secure access to valuable insights. With robust security features and seamless integration with leading data visualization tools, AWS provides a comprehensive solution for organizations to leverage the transformative power of ad-hoc querying and make data-driven decisions with agility and confidence.
Click here to read about Data Value
