








 Media Coverage
Media Coverage Press Release
Press Release
RAG-Powered Named Entity Recognition (NER)
Building Custom Models with RAG and NER
Introduction to RAG-Powered NER Techniques
USEReady’s Guide to Custom Model Building
Named Entity Recognition (NER) is an important component of Natural Language Processing (NLP). NER helps with the recognition and categorization of predefined entities such as names, dates, locations, etc. present in the given text input. However, developing a NER solution which is both efficient and effective, can handle complicated input and can be well-generalized across different domains is a difficult and challenging task. A custom NER model however can be extremely useful tool for information extraction applications. Possible ways of doing this include training a traditional Machine learning NER model and finetuning a large language model (LLM).
Introduction to RAG and NER
Benefits of RAG for Custom NER Models
Step-by-Step Guide to Implementing RAG-Powered NER
Real-World Applications of Custom NER Models
Overview of RAG for NER
Key Steps for Building Custom Models
Advanced Techniques for NER Optimization
Case Studies in RAG-Powered Model Implementation
Real-world Applications
NER is frequently used to extract important information from unstructured text in a variety of industry sectors. In healthcare, for instance, it helps in extracting patient details from clinical notes, enabling better patient management. To support market analysis in the finance industry, NER helps extracting significant financial events from news items. NER is used by customer care systems to effectively process and route consumer inquiries. These use cases showcase just how crucial, reliable NER systems can be in practical situations.
Traditional and LLM-based NER Model Challenges
Whether it is Traditional ML-based or a LLM based model, both approaches have their own challenges. These include:
Generalization Capabilities
Traditional ML-based models often struggle with complex or unseen data. They might work well on the training data, but in real-world scenarios they fail to identify entities accurately with a different phrasing or context.
Data Requirements
Training a robust and reliable NER model requires significant amount of labelled data. Many organisations may find this to be an impractical approach as this can be a time consuming and expensive process.
Cost and Computational Bottleneck
Training LLMs for NER tasks requires a large amount of computing power. On the other hand, there can be significant expenses associated with employing API-based models such as GPT-4, Gemini, or Claude, particularly when it comes to training or fine-tuning.
Limitations of Few-Shot Learning
Few-shot learning, in which LLMs are trained with a small set of examples, can reduce data requirements to some extent. However, it still falls short in many cases due to the limitations in the number of examples it can effectively utilize.
RAG to the Rescue!
A potential solution for these issues is a Retrieval Augmented Generation (RAG) based approach. RAG models combine the strengths of retrieval and generation techniques:
Dynamic Retrieval
Based on the user’s input, the RAG system dynamically retrieves the most similar examples from the dataset. This means the model is continually informed by the most relevant context, improving its ability to generalize without extensive retraining.
Cost-Effective and Efficient
RAG models don’t require extensive fine-tuning of LLMs, making them computationally less expensive. This opens up the possibility of using powerful LLMs for NER tasks without the hefty computational cost.
Reduced Data Requirements
Unlike large training datasets, RAG requires you to provide a small number of examples of good quality.
Flexibility and adaptability
RAG allows you to easily update or expand your example set without retraining, making it ideal for evolving NER requirements.
Practical Implementation
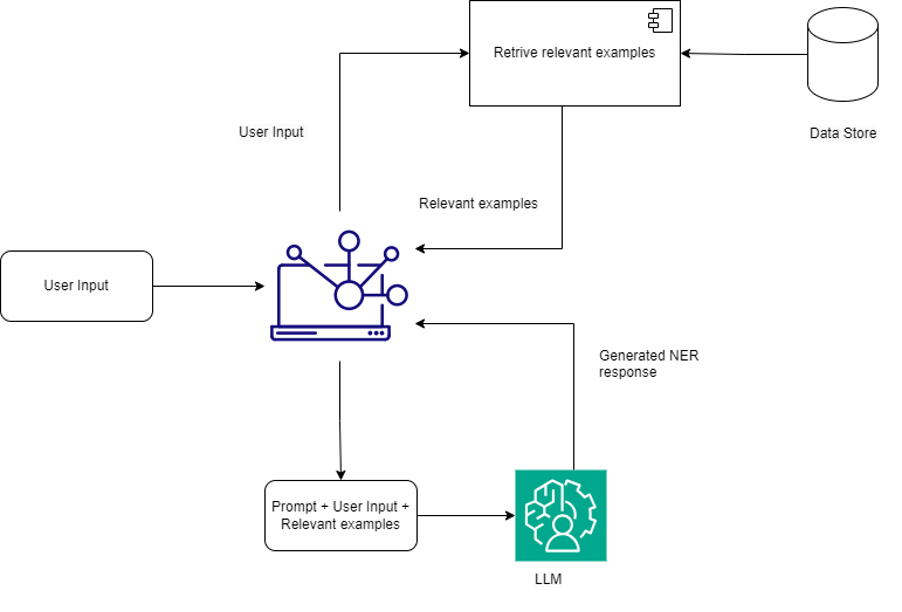
Implementing a RAG-based NER system involves a few key steps:
Initial Sample Creation
Start by creating a small set of high-quality annotated examples. These should cover a variety of scenarios within the specific domain of interest.
Retrieval System Setup
Implement a retrieval mechanism that can efficiently fetch the most relevant examples based on the input text. This could involve using embeddings or other similarity measures to find the best matches.
Integration with Generation
Craft prompts that effectively combine the retrieved examples with the user’s input for the LLM. Leverage existing LLMs (like GPT-4, Claude, etc.) to perform NER based on the RAG-enhanced prompts.
A Scenario
Let’s consider a hypothetical case where a legal firm implements a RAG-based NER system to classify and identify legal entities from contracts. Initially, a small set of high-quality annotated examples, covering a range legal terms and contexts, was created. The retrieval system was set up using Pinecone to fetch relevant examples based on the input text. By integrating these examples with the user’s input and using GPT-4 for generation, the firm observed significant improvements in the accuracy and flexibility of their NER system, while reducing the need for extensive retraining.
Some Drawbacks
While RAG based NER offers many advantages, it’s important to take into account some potential drawbacks:
Knowledge Base Dependence
RAG models rely on retrieving similar examples from a knowledge base. The quality and comprehensiveness of this knowledge base has a significant impact on the accuracy of the NER system; if the base lacks relevant examples, the model may struggle with unseen entities or domains.
Prompt Engineering Challenges
Creating effective prompts is critical to RAG’s success. Ineffective prompts can cause the LLM to misinterpret the data or neglect to focus on the relevant aspects for NER.
Explainability and Bias
Just like LLMs, RAG models can be difficult to understand. Understanding the reasoning behind the model’s assignment of a specific entity label can be challenging, which makes it challenging to spot and correct any biases in the training set or knowledge base.
Increased Inference Time
Compared to traditional ML approaches, RAG-based NER can take longer to process an input due to the retrieval and generation steps involved. This can be a drawback for real-time applications requiring low latency.
Conclusion
In essence, a RAG-based NER system allows you to create custom NER models with just a handful of high-quality samples. The model then leverages its retrieval capabilities to find relevant supporting examples based on the user’s specific inputs. This significantly reduces the time, cost, and resources required to build effective NER systems.
By combining human expertise in crafting relevant examples with the power of retrieval and generation, RAG offers a promising approach for building custom NER models that are both efficient and adaptable.

