Building a Modern Data Stack: Transforming Your Data Infrastructure
Key Components and Best Practices for Modern Data Stacks
Empowering Your Organization with a Modern Data Infrastructure
The data eco-system metamorphosis over the past few years has been more pronounced than probably the decades preceding it. Cloud has created the proverbial flat world for businesses. Cost is no longer a barrier. Any company whether a global fortune 500 company or a neighborhood start-up both have access to the same services and applications at the click of a button.
Understanding the Components of a Modern Data Stack
Best Practices for Implementing a Modern Data Infrastructure
Cloud readily offers the scale and agility that help companies survive, thrive and grow in this fast-paced, ever changing business ecosystem. The race is not about catching up with competitors but creating a truly differentiated product.
Online banking, online-shopping, online meetings, online everything… this has spawned an entire new paradigm for businesses, have also realized that digitization is the way forward and are not hesitant to experiment with new technologies and new processes. Technologies like AI, ML, Big Data, Data Science are shepherding businesses. They are proving to be catalyst in this epoch defining journey.
Choosing the Right Tools for Your Modern Data Stack
Achieving Data-Driven Success with a Modern Data Stack
Digitization has bought speed and scale of unheard magnitude. The has posed challenges to the traditional approaches that data architects have sworn by over the last five decades or so. Companies can no longer just scale their on-prem data infrastructure and hope to ride the wave. Traditional, textbook templatized architectural approaches can no longer collect, hold, manage and process data to support this dynamically changing environment. The efforts to even “keep the lights on” are simply too expensive and cumbersome.
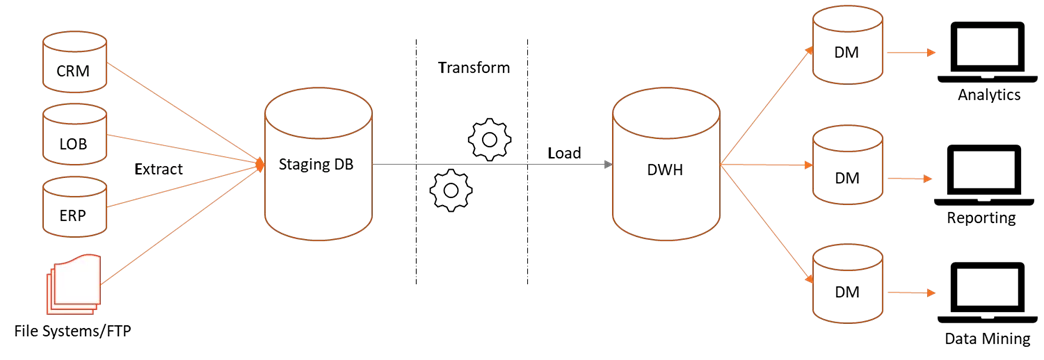
While companies & data architects agree without any ambiguity that cloud is the way forward, a plethora of offerings from different companies in the market may lead CDO to decision paralysis which at times may be detrimental to the organization. Worse still, bad choices may put the very survival at stake.
The Role of Data Warehousing in a Modern Data Stack
Optimizing ETL Processes for Efficient Data Integration
Any modern data stack must be built on the premise scale, speed, agility, automation and efficiency; efficiency being the key.
Gone are the days when IT systems teams took months on end to deliver even the simplest of data requirement. As discussed earlier, the era of digitization & cloud technologies has created a very pronounced and vocal demand for efficient data collection strategies.
A key shift in data retention strategies in the modern data eco-system is a definite evolution of data lakehouse as the central data repository. Data lakehouses have gained in popularity due to ready access to data in its native form, cheap cost, flexibility, support to both structured & unstructured data within the same data platform.
Leveraging Data Integration Tools for Seamless Data Flow
Harnessing Analytics Platforms for Actionable Insights
Snowflake, the cloud native, intelligent data platform perfectly aligns with this mission. Helping companies collect, hold and consume data in a simple, user-friendly interface offering instant elasticity at affordable, predictable prices.
It has by far and conclusively left behind competition; not just traditional on-prem applications but also offerings from public cloud service providers due to its revolutionary architecture, robust industry leading security features and access control capabilities for data privacy and org compliance.
While Snowflake offers an efficient way to hold & consume vast amounts of data, an important KPI for the data team’s success is how efficiently they can collect and support data consumption by a variety of applications, processes.
In this time and era of APIs, click stream data, SaaS applications companies understand that data is a perishable commodity which has value for only a finite period of time after this it’s relevance to business diminishes exponentially. In this scenario, the role of data teams has changed from that of data owners to that of provisioning data. It’s no longer an acceptable outcome that ETL jobs take hours on end if not days to load aggregated data into structured databases.
This has spawned a type of data practitioners — data engineers, whose primary role is to design efficient data pipelines to land raw into the target repository in the quickest possible time within acceptable costs and data quality parameters.
Matillion offers a simple, elegant technique that solves not just this problem for data engineers. While it is possible to use the likes of python or similar programming languages, the maintenance overhead makes it a less than desirable option for most use cases.
It is purpose-built, cloud only ELT tool exclusively designed for Snowflake. It offers wide spread of native API connectors that makes designing any data pipeline a breeze. It’s credits-based pricing model is simple, transparent and surprisingly affordable to even the smallest start-ups working with tight budgets. Data is landed into Snowflake in a matter of few minutes as compared to hours or days traditional ETL tools normally take.
The CDOs mandate has evolved from just managing data repositories to fostering a culture of data driven operations, enabling a new breed of knowledge workers who are data fluent. Self-service analytics is an outcome of this conscious effort. A nuanced pivot here has been a gradual shift from data teams owning data operations while business teams consuming information via data viz. or spreadsheets to derive insights to one where data fluent analysts build models to support their own analysis and insights generation.
dbt, an ANSI SQL only tool is a clear winner and emerging market leader in the self-service analytics space. It offers both an open source CLI based version and cloud version. While the user experience is same in both cases, the cloud version is hosted solution offered by getdbt.com. It offers a development framework that combines SQL code with the best practices of software engineering to build reusable, modular components for fast, reliable transformations of data residing in Snowflake. From code versioning to deployment and documentation, quality testing dbt automates the entire analytical engineering process.
Key Takeaways:
- Data is a vital asset for any organization, but it has finite life. Any delay is provisioning data is lost business opportunity.
- Technology is only an enabler; the real value of data is derived via insights generated.
- The move to cloud is unidirectional and permanent.
- Data ecosystem is rapidly shifting towards an event-based, de-coupled or loosely coupled architecture where individual tools add value by efficiently performing just one function.
- The modern data stack is fragmented with multiple layers like data collection & ingestion, storage, modelling, reporting-to name a few. To succeed, data teams must leverage best-in-class vendor for each layer, like the one we discussed.
- Successful implementation depends on not just on the right tools, but also the right methodology. Without the rigor of Software Engineering Best Practices, the data stack cannot deliver value.
- Reliability, scalability, agility, efficiency and cost are the key drivers of this change.
