








 Media Coverage
Media Coverage Press Release
Press Release
Data Management Strategies with Snowflake
Leveraging Snowflake for Data Optimization
USEReady’s Guide to Structured and Unstructured Data
Unstructured data, which defies conventional data models or schemas, often includes text-rich sources such as survey responses and social media interactions, as well as multimedia files like images, videos, and audio recordings. Handling this type of data can be a significant challenge, especially with the growing importance of AI. However, Snowflake provides tools and features that can help manage, process, and store unstructured data effectively.
In this blog, we will be going through some of the functionalities and tools given by snowflake to manage unstructured data.
Understanding Unstructured and Structured Data
Snowflake’s Approach to Unified Data Management
Best Practices for Managing Complex Data Sets
Use Cases for Snowflake in Data Management
Overview of Snowflake’s Data Capabilities
Techniques for Handling Unstructured Data
Structuring and Querying Data in Snowflake
Real-World Applications of Snowflake’s Data Solutions
Main Ways of Handling Unstructured Data
Snowflake Stages and External Storage Integration:
- Internal and External Stages: Snowflake can store unstructured data in internal stages (within Snowflake) and external stages (cloud storage such as AWS S3, Azure Blob Storage, Google Cloud Storage).
- Data Ingestion: Using Snowflake’s built-in file format support, data engineers can easily ingest various unstructured data formats, including JSON, Avro, Parquet, and XML. External tables and the COPY INTO command facilitate efficient data loading.
Snowpark and User-Defined Functions (UDFs):
- Snowpark: This developer framework supports Java, Scala, and Python, allowing users to process unstructured data natively within Snowflake. Snowpark eliminates the need for separate processing engines by enabling data processing directly within Snowflake’s infrastructure.
- Python UDFs: These allow the execution of Python code within Snowflake, taking advantage of the Python ecosystem for tasks such as text extraction, image processing, and sentiment analysis. For example, PyPDF2 can be used for PDF processing, while TensorFlow can be employed for image recognition tasks (Snowflake) (Snowflake).
Unstructured Data Management:
- Secure Access and Sharing: Snowflake provides various methods for secure file access, including scoped URLs, file URLs, and pre-signed URLs. These URLs enable temporary or permanent access to files without compromising security, ideal for sharing data within and across organizations (Snowflake).
- Directory Tables: These tables provide metadata about files stored in a stage, enabling efficient management and retrieval of unstructured data (Snowflake Developers).
Advanced Analytics and Machine Learning:
- Custom ML Models: Snowflake supports the integration of custom machine learning models for processing unstructured data. Models can be loaded dynamically within UDFs or stored procedures to perform tasks such as image classification and object detection (Snowflake).
- Integration with ML Tools: Partnerships with companies like Clarifai, Impira, and Veritone extend Snowflake’s capabilities, enabling advanced analytics and insights from unstructured data (Snowflake).
Processing Unstructured Data
Unstructured data, which includes text, images, videos, and other non-tabular formats, often presents unique challenges for data processing and analysis. Snowflake provides a comprehensive set of tools and capabilities to manage, process, and analyze unstructured data, enabling organizations to extract valuable insights and drive data-driven decision-making. Snowflake supports the following features to help you process unstructured data:
- External functions: External functions are user-defined functions that you store and execute outside of Snowflake. With external functions, you can use libraries such as Amazon Textract, Document AI, or Azure Computer Vision that cannot be accessed from internal user-defined functions (UDFs).
- User-Defined Functions and Stored Procedures: Snowflake supports multiple ways to read a file within Java or Python code so that you can process unstructured data or use your own machine learning models in user-defined functions (UDFs), user-defined table functions (UDTFs), or stored procedures.
Processing Unstructured Data with UDF and Procedure Handlers
Snowflake’s support for User-Defined Functions (UDF) and stored procedures, particularly python enhances the capabilities to process and analyze unstructured data. Leveraging python within snowflake offers several advantages, enabling complex data transformations, advanced analytics and seamless integration with machine learning models. The main advantages of using Python UDFs and Procedures in Snowflake are:
- Flexibility and Power: Python provides a vast ecosystem of libraries (e.g., NumPy, Pandas, Scikit-learn, NLTK) that can be used for data manipulation, analysis, and machine learning. This flexibility allows you to perform complex operations directly within Snowflake.
- Seamless Integration: Python UDFs and stored procedures can easily integrate with existing data workflows in Snowflake, reducing the need to move data between platforms.
- Scalability: Snowflake’s architecture ensures that Python UDFs and procedures can scale to handle large volumes of data efficiently.
- Ease of Use: Writing UDFs and procedures in Python is straightforward, especially for data scientists and engineers familiar with the language.
Let’s understand this better using an example.
Text Sentiment Analysis for Customer feedback
In this particular use case, we want to analyze customer feedback collected from various sources (e.g., surveys, emails, social media) to determine the sentiment expressed in the text. We’ll use Python UDFs and stored procedures within Snowflake to process this unstructured text data.
Step 1
Setting up the Environment
Ensure that your Snowflake account is set up to use Python for UDFs and stored Procedures.
- Ensure that you have ACCOUNTADMIN role (or a role with equivalent permissions) to enable the features and manages the configurations
- Developers will need the ‘CREATE FUNCTION’ and ‘CREATE PROCEDURE’ priveleges on the database and schema where the functions and procedures will be created
- Ensure that your snowflake account has Snowspark for python enabled
Step 2
Create the Customer Feedback Table
Create a table called ‘Customer_Feedback’ with a column ‘feedback_text’ containing unstructured data
CREATE OR REPLACE TABLE customer_feedback (
id INT,
feedback_text STRING
);Step 3
Ingesting Sample Data
Insert sample data int the ‘customer_feedback’ table.
INSERT INTO customer_feedback (id, feedback_text) VALUES
(1, 'I love the new product features!'),
(2, 'The customer service was terrible.'),
(3, 'I had a great experience shopping here.'),
(4, 'The website is very user-friendly.'),
(5, 'I am not satisfied with the product quality.');Step 4
Creating a Python UDF for Sentiment Analysis
Create a Python UDF that uses the ‘ TextBlob’ library to analyze the sentiment of the feedback text.
CREATE OR REPLACE FUNCTION analyze_sentiment(feedback STRING)
RETURNS FLOAT
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
HANDLER = 'analyze_sentiment'
AS
$$
from textblob import TextBlob
def analyze_sentiment(feedback):
analysis = TextBlob(feedback)
return analysis.sentiment.polarity
$$;Step 5
Creating a Stored Procedure to Process Feedback Data
Create a stored procedure that iterates through the ‘customer_feedback’ table, applies the ‘analyze_sentiment’ UDF to each feedback entry, and stores the result in a new table.
CREATE OR REPLACE PROCEDURE process_feedback()
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
HANDLER = 'process_feedback'
AS
$$
def process_feedback(session):
# Create a table to store the sentiment results
session.sql("CREATE OR REPLACE TABLE feedback_sentiment (id INT, sentiment FLOAT)").collect()
# Fetch feedback data
feedback_data = session.table("customer_feedback").collect()
# Analyze sentiment and insert results into the new table
for row in feedback_data:
sentiment = analyze_sentiment(row['feedback_text'])
session.sql(f"INSERT INTO feedback_sentiment (id, sentiment) VALUES ({row['id']}, {sentiment})").collect()
return "Feedback processing complete."
$$;Step 6
Executing the Stored Procedure
Executing the stored procedure to process the feedback data.
CALL process_feedback();Step 7
Querying the Results
Query the ‘feedback-sentiment’ table to see the results of the sentiment analysis.
SELECT * FROM feedback_sentiment;Output
| Id | Sentiment |
|---|---|
| 1 | 0.5 |
| 2 | -1.0 |
| 3 | 0.8 |
| 4 | 0.3 |
| 5 | -0.5 |
Advantages Over Traditional Methods
- End-to-End Solution: By processing data entirely within Snowflake, you avoid the complexity and overhead of transferring data between different platforms.
- Performance: Snowflake’s architecture is optimized for high performance, enabling faster data processing and analysis.
- Simplicity: Using Python UDFs and stored procedures simplifies the workflow, allowing data scientists to leverage familiar tools and libraries directly within the data platform.
- Security and Compliance: Keeping the data within Snowflake ensures that it remains within a secure, governed environment, adhering to compliance requirements.
- Scalability: Snowflake can seamlessly scale to accommodate increasing data volumes, ensuring that your sentiment analysis remains performant as the amount of feedback grows.
Reference links:
https://docs.snowflake.com/en/user-guide/unstructured-intro
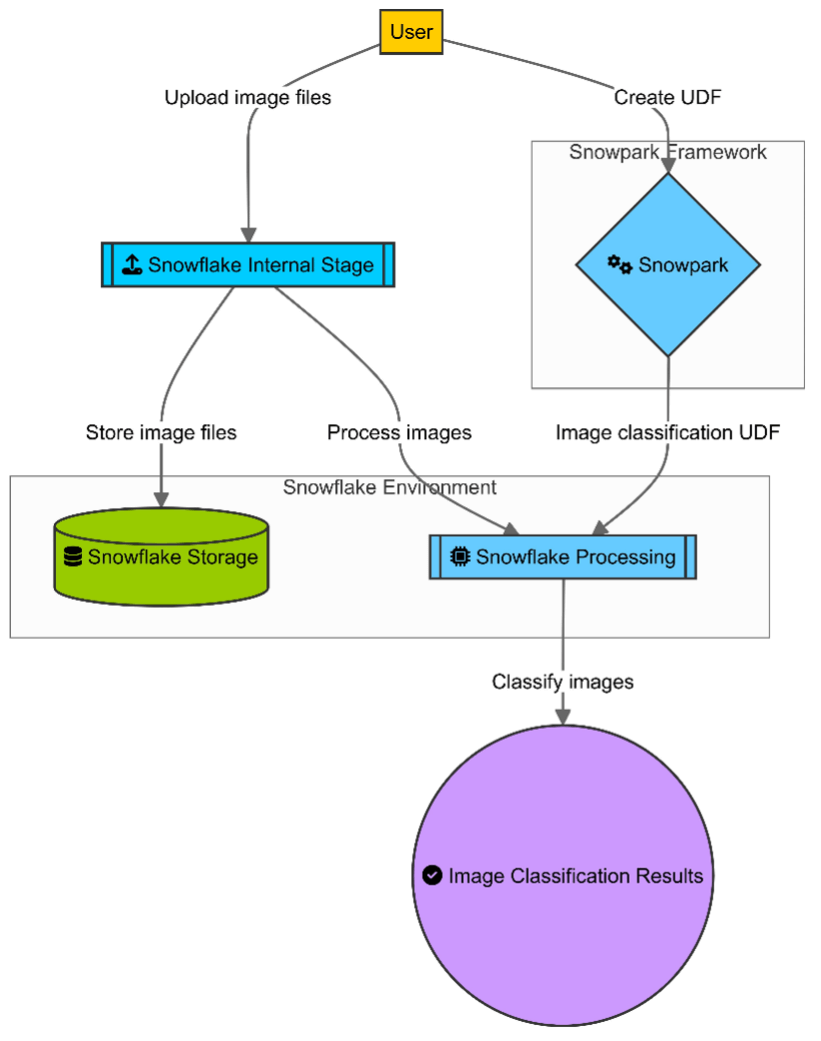
Handling Unstructured Data using Snowpark
Snowpark is a developer framework introduced by Snowflake to enable the processing of data using familiar programming languages like Java, Scala, and Python. This framework allows users to write code that executes directly within Snowflake’s data platform, eliminating the need for separate processing engines. By integrating data processing into Snowflake’s infrastructure, Snowpark ensures that the data remains secure and accessible while leveraging Snowflake’s powerful computational capabilities.
Let’s go through Snowpark’s capability using an example.
Image Classification with Snowpark
Step 1
Setup
Ensure that your Snowflake account is configured for Snowpark and that you have access to Snowflake storage. You can do this by following this example configuration script.
-- Ensure you are using a supported Snowflake edition
USE DATABASE my_database;
USE SCHEMA my_schema;
-- Enable Snowpark capabilities
ALTER ACCOUNT SET ALLOW_EXTERNAL_FUNCTIONS = TRUE;
-- Create an internal stage for storing unstructured data files
CREATE OR REPLACE STAGE my_image_stage;
-- Upload a sample image to the internal stage
PUT file:///path/to/your/image.jpg @my_image_stage;
-- Grant necessary privileges to the role
GRANT USAGE ON STAGE my_image_stage TO ROLE my_role; Step 2
Stage Creation
Create an internal stage to store image files.
CREATE OR REPLACE STAGE my_image_stage;Step 3
Uploading Images
Upload images to the stage using Snowflake’s PUT command.
PUT file:///path/to/your/image.jpg @my_image_stage;Step 4
Creating the UDF for Image Classification
Create a Python UDF using Snowpark to classify images. We use the tensorflow library for image classification.
CREATE OR REPLACE FUNCTION classify_image(image_url STRING)
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.9'
PACKAGES = ('snowflake-snowpark-python', 'tensorflow')
HANDLER = 'image_classifier'
AS
$$
from snowflake.snowpark.files import SnowflakeFile
import tensorflow as tf
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.mobilenet_v2 import MobileNetV2, preprocess_input, decode_predictions
import numpy as np
import io
model = MobileNetV2(weights='imagenet')
def image_classifier(image_url):
# Open image from Snowflake storage
file = io.BytesIO(SnowflakeFile.open(image_url, 'rb').read())
img = image.load_img(file, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array = preprocess_input(img_array)
predictions = model.predict(img_array)
decoded_predictions = decode_predictions(predictions, top=1)[0][0]
return decoded_predictions[1] # Return the class name
$$; Here we have used mobilenet_v2 model as an image classification model but we can use any other image classification or detection models like CNN, ResNet, AlexNet etc.
Step 5
Using UDF in a Query
We have defined the function in the above step now we will be using it to classify the image that we have stored in the internal stage.
SELECT file_name, classify_image(file_url) AS classification
FROM (
SELECT
relative_path AS file_name,
build_scoped_file_url('@my_image_stage', relative_path) AS file_url
FROM directory(@my_image_stage)
);
Advantages of Snowpark for Handling Unstructured Data
- Unified Platform:
- Integrated Environment: Process unstructured data within Snowflake, reducing the complexity and overhead of moving data between systems.
- Simplified Architecture: Minimize the need for external ETL tools and separate processing clusters.
- Language Flexibility:
- Multiple Language Support: Utilize Java, Scala, or Python, leveraging the vast ecosystem of libraries available in these languages.
- Custom Processing: Write tailored processing logic for unstructured data, such as natural language processing, image recognition, and more.
- Scalability and Performance:
- Parallel Processing: Leverage Snowflake’s scalable architecture to process large volumes of data in parallel.
- Elastic Compute: Scale Snowflake’s compute resources up or down based on workload needs.
- Security and Governance:
- Data Security: Maintain processing within Snowflake’s secure environment.
- Data Governance: Utilize Snowflake’s built-in data governance features for secure data management.
Structured data in snowflake
Structured data refers to highly organized information that is easily searchable and typically stored in tabular format within relational databases or spreadsheets. This data conforms to a specific schema, meaning it has a pre-defined model with clear, consistent fields such as names, dates, addresses, and numbers. Examples include customer records, financial transactions, and sensor data.
Snowflake Capabilities for Handling Structured Data
Snowflakes architecture and features support various features and data handling capabilities to handle and process structured data. Here is an overview of Snowflake’s capabilities:
1. Data Warehousing and Processing
Snowflake’s core strength lies in its ability to serve as a scalable and performant data warehouse. It can ingest and process massive amounts of structured data quickly. Key features include:
- Separation of Storage and Compute: Snowflake allows for independent scaling of storage and compute resources, ensuring optimal performance and cost-efficiency.
- Automatic Scaling: Automatic scaling of compute resources to handle varying workloads without manual intervention.
- Multi-cluster Warehouses: These provide seamless scaling for concurrent user queries and workload balancing.
2. Data Integration and ETL
Snowflake provides robust tools for integrating and transforming structured data:
- Snowpipe: A continuous data ingestion service that loads data as soon as it arrives in external stages, such as AWS S3, Azure Blob Storage, or Google Cloud Storage.
- Data Transformation: Snowflake supports SQL-based transformation using its rich set of SQL functions and integration with ETL/ELT tools like Talend, Informatica, and dbt.
3. Data Sharing and Collaboration
Snowflake’s unique architecture allows for secure data sharing without the need for data replication. Features include:
- Secure Data Sharing: Enables organizations to share live data in real-time with external partners without creating copies.
- Data Marketplace: Snowflake Data Marketplace allows organizations to access and share data sets, enhancing collaboration and insights.
4. Machine Learning and AI Integration
Snowflake supports the integration of machine learning and AI workloads through various means:
- Snowpark: Snowflake’s developer framework that allows data engineers, data scientists, and developers to write code in languages like Java, Scala, and Python and execute it directly within Snowflake. This is particularly useful for data preparation, feature engineering, and model training.
- Integration with ML Tools: Snowflake integrates seamlessly with machine learning platforms such as DataRobot, H2O.ai, and Amazon SageMaker, allowing users to build, train, and deploy models directly from Snowflake data.
- UDFs and UDTFs: User-defined functions (UDFs) and table functions (UDTFs) allow for custom processing of data within SQL queries, which can be leveraged for various AI/ML tasks.
5. Generative AI Capabilities
Generative AI, which involves creating new content from existing data, benefits from Snowflake’s advanced data handling capabilities:
- Model Training and Inference: With Snowpark and integrated ML tools, generative models (such as GANs, transformers, etc.) can be trained and run on Snowflake data.
- Data Preparation: Structured data stored in Snowflake can be easily transformed and prepared for training generative AI models.
- Real-time Data Processing: Snowflake’s real-time data ingestion and processing capabilities ensure that generative AI models are trained on the most current data.
6. Advanced Analytics
Snowflake’s advanced analytics capabilities support the exploration and analysis of structured data:
- Analytical Functions: Snowflake offers a comprehensive set of SQL functions for analytics, including window functions, statistical functions, and geospatial functions.
- Data Visualization: Integration with BI tools like Tableau, Looker, and Power BI enables users to create interactive dashboards and visualizations.
Processing structured data in snowflake
Snowflake provides various methods to process structured data efficiently, leveraging its powerful SQL engine, seamless integrations, and unique architectural features. Here, we’ll explore these methods in detail and illustrate them with examples.
SQL-Based Processing
Snowflake’s primary method for processing structured data is through SQL queries. It supports a rich set of SQL commands for data manipulation, aggregation, and transformation.
Let’s understand this via an example:
Suppose you have a table sales with the following columns: order_id, customer_id, order_date, amount. You want to calculate the total sales per customer.
SELECT customer_id, SUM(amount) AS total_sales
FROM sales
GROUP BY customer_id; This query aggregates the sales data by customer_id and calculates the total sales for each customer.
Stored Procedures
Stored procedures allow you to encapsulate complex business logic and data processing workflows. Snowflake supports stored procedures written in JavaScript. Example: A stored procedure to update sales data with discounts.
CREATE OR REPLACE PROCEDURE apply_discount()
RETURNS STRING
LANGUAGE JAVASCRIPT
EXECUTE AS CALLER
AS
$$
var statement1 = snowflake.createStatement({sqlText: `
UPDATE sales
SET amount = amount * 0.9
WHERE amount > 100;
`});
statement1.execute();
return "Discounts applied to high-value sales.";
$$; You can call this stored procedure to apply a 10% discount to sales over $100.
CALL apply_discount();User-Defined Functions (UDFs)
UDFs enable custom processing logic within SQL queries. Snowflake supports both SQL-based and JavaScript-based UDFs.
Example: A SQL UDF to calculate a customs sales tax.
CREATE OR REPLACE FUNCTION calculate_tax(amount FLOAT)
RETURNS FLOAT
LANGUAGE SQL
AS
$$
amount * 0.07
$$;
SELECT order_id, amount, calculate_tax(amount) AS tax
FROM sales; The UDF calculates a 7% sales tax for each order.
User-Defined Table Functions (UTDFs)
UDTFs return a set of rows, allowing more complex data transformations. They are often used for tasks like data parsing and splitting.
Example: A UDTF to split comma-separated customer ID’Ds into individual rows.
CREATE OR REPLACE FUNCTION split_customers(customer_ids STRING)
RETURNS TABLE (customer_id STRING)
LANGUAGE JAVASCRIPT
AS
$$
var result = [];
customer_ids.split(',').forEach(function(id) {
result.push({ CUSTOMER_ID: id.trim() });
});
return result;
$$;
SELECT * FROM TABLE(split_customers('1,2,3,4,5'));This UDTF splits the string ‘1,2,3,4,5’ into separate rows.
Snowpipe
Snowpipe automates the continuous loading of data into Snowflake tables as soon as it arrives in external stages. Let’s understand how Snowpipe works with an example.
Setting up Snowpipe to load data from an S3 bucket
Step 1
Create a stage to point to the S3 bucket.
CREATE OR REPLACE STAGE my_stage
URL='s3://my-bucket/data/'
CREDENTIALS=(AWS_KEY_ID='YOUR_AWS_KEY' AWS_SECRET_KEY='YOUR_AWS_SECRET'); Step 2
Create a table to store the ingested data.
CREATE OR REPLACE TABLE sales_staging (
order_id STRING,
customer_id STRING,
order_date DATE,
amount FLOAT
);Step 3
Create a Snowpipe to load data into the table.
CREATE OR REPLACE TABLE sales_staging (
order_id STRING,
customer_id STRING,
order_date DATE,
amount FLOAT
);Step 4
Configure notifications in S3 to trigger Snowpipe when new files arrive.
Hybrid Tables
Hybrid tables combine the best of transactional and analytical processing, providing low-latency queries for operational workloads while maintaining high throughput for analytical queries.
Example: Creating and Querying a Hyper Table
CREATE OR REPLACE HYBRID TABLE customer_orders (
order_id INT,
customer_id INT,
order_date TIMESTAMP,
amount DECIMAL(10, 2)
);
-- Inserting data into Hybrid Table
INSERT INTO customer_orders VALUES
(1, 101, '2024-01-01 10:00:00', 150.00),
(2, 102, '2024-01-02 11:00:00', 200.00);
-- Querying the Hybrid Table
SELECT customer_id, SUM(amount) AS total_amount
FROM customer_orders
GROUP BY customer_id;Hybrid Tables in Snowflake represent an advanced feature designed to bridge the gap between transactional (OLTP) and analytical (OLAP) workloads. They provide a unified platform to handle both types of workloads efficiently, ensuring low-latency queries for operational tasks and high throughput for analytical queries.
Key Features of Hybrid Tables
1. Transactional Consistency (ACID Compliance)
- Hybrid Tables support Atomicity, Consistency, Isolation, and Durability (ACID) properties, ensuring reliable and consistent transaction processing.
- This allows businesses to run transactional workloads with the assurance that data integrity is maintained.
2. Optimized for Mixed Workloads
- Hybrid Tables are designed to handle both OLTP and OLAP workloads. This dual capability means that users can perform real-time operational queries while also running complex analytical queries on the same dataset.
- This optimization reduces the need for separate databases for transactional and analytical processing.
3. Low-Latency Queries
- Hybrid Tables provide fast query performance for operational workloads, ensuring that real-time applications and services can access and manipulate data quickly.
- This low-latency performance is crucial for applications that require immediate feedback, such as customer-facing applications or inventory management systems.
4. High Throughput for Analytical Queries
- In addition to handling transactional workloads, Hybrid Tables support high-throughput analytical queries. This allows data analysts and data scientists to run complex queries and aggregations efficiently.
- The architecture of Hybrid Tables ensures that large-scale data processing tasks can be performed without significant performance degradation.
5. Unified Data Management
- By combining transactional and analytical processing in a single table, Hybrid Tables simplify data management. There is no need to ETL (Extract, Transform, Load) data between different systems, reducing data movement and duplication.
- This unified approach also simplifies data governance and security, as all data resides within the same platform.
6. Scalability and Flexibility
- Hybrid Tables benefit from Snowflake’s scalable architecture. Users can scale compute resources independently of storage, ensuring that performance can be adjusted based on workload requirements.
- This flexibility allows businesses to handle varying workloads without over-provisioning resources.
Advantages of Hybrid Tables
1. Simplified Architecture
- Reduces the complexity of maintaining separate systems for transactional and analytical processing.
- Consolidates data management, security, and governance into a single platform.
2. Cost Efficiency
- Minimizes the need for multiple systems and data duplication, leading to cost savings in infrastructure and maintenance.
- Efficient resource utilization through Snowflake’s scalable compute and storage.
3. Real-Time Insights
- Enables real-time operational insights and analytics on the same dataset, supporting faster decision-making.
- Improves the ability to respond to business events and trends as they occur.
4. Enhanced Data Consistency
- Ensures data consistency across both transactional and analytical queries, reducing the risk of data discrepancies.
- Maintains a single source of truth for all data-related operations.
5. Improved Collaboration
- Facilitates collaboration between operational teams and analytics teams by providing a shared dataset.
- Supports a unified view of data, enabling cross-functional analysis and reporting.
Automated Data Quality Management in Snowflake
Automated Data Quality Management (ADQM) in Snowflake has been significantly enhanced to ensure that data integrity and quality are maintained automatically with minimal manual intervention. The latest advancements incorporate AI-driven data anomaly detection, automatic schema evolution, and comprehensive data lineage tracking. These features help organizations maintain high data quality standards, ensure data consistency, and improve data governance.
Key Components of Automated Data Quality Management
1. AI-Driven Data Anomaly Detection
AI-driven data anomaly detection uses machine learning algorithms to identify patterns and detect outliers or anomalies in the data automatically. This helps in proactively identifying and addressing data quality issues before they impact downstream processes.
Advantages:
- Proactive Quality Control: Detect anomalies in real-time, allowing for immediate corrective actions.
- Scalability: Handle large volumes of data efficiently without manual inspection.
- Improved Accuracy: Machine learning models can learn from historical data and improve over time, reducing false positives and negatives.
2. Automatic Schema Evolution
Automatic schema evolution ensures that changes in data schemas are managed seamlessly without interrupting data ingestion and processing workflows. This feature automatically adjusts the schema of tables in response to changes in the incoming data structure, such as adding new columns or changing data types.
Advantages:
- Seamless Integration: Automatically adapts to schema changes without requiring manual intervention or downtime.
- Consistency: Maintains schema consistency across datasets, ensuring that data consumers always see a coherent structure.
- Flexibility: Supports agile data integration and accommodates evolving business requirements.
3. Data Lineage Tracking
Data lineage tracking provides a comprehensive view of the data flow from source to destination, capturing all transformations and data movements. This feature is crucial for data governance, compliance, and understanding the impact of changes in the data pipeline.
Advantages:
- Transparency: Offers complete visibility into data transformations, helping identify the origin and transformations applied to any piece of data.
- Compliance: Supports regulatory compliance by maintaining detailed records of data handling and processing activities.
- Impact Analysis: Helps in understanding the downstream impact of data changes, aiding in troubleshooting and optimizing data pipelines.
Conclusion
Snowflake’s comprehensive platform empowers users to effectively manage and process both structured and unstructured data. Its integration with various tools and features like Snowpark and User Defined Functions provides a flexible and powerful environment for data scientists and analysts. But while in this blog we explored some of Snowflake’s core functionalities, there’s much more to discover. We encourage you to delve deeper into Snowflake’s documentation and explore its capabilities further. As the data landscape continues to evolve, so does Snowflake, providing innovative solutions to meet the evolving needs of data professionals.
Reference links
Snowflake documentation: Getting Started – Snowflake Documentation
Snowpark Overview: Snowpark API | Snowflake Documentation
Hybrid tables: Hybrid tables | Snowflake Documentation
Data collaboration and clean rooms: Snowflake for Collaboration and Data Sharing | Snowflake Workloads
Native streaming process: Introduction to Streams | Snowflake Documentation
Snowflake Documentation on Data Quality Managament: Introduction to Data Quality and data metric functions | Snowflake Documentation
AI driven Data Management: Navigating the Future: Snowflake’s Role in an AI-Driven Data Landscape (linkedin.com)
Snowflake Data Lineage Overview: Data Lineage: Documenting the Data Life Cycle | Snowflake

