








 Media Coverage
Media Coverage Press Release
Press Release
Understanding Fuzzy Matching for Data Cleansing
Practical Applications of Fuzzy Matching in Alteryx
Enhancing Data Accuracy with Alteryx Fuzzy Matching
Introduction to Fuzzy Matching and Its Importance
Setting Up and Configuring the Fuzzy Match Tool in Alteryx
Real-World Use Cases of Fuzzy Matching in Data Cleaning
Best Practices for Optimizing Fuzzy Matching Accuracy
Key Concepts Behind Fuzzy Matching in Alteryx
How to Handle Common Data Matching Challenges
Evaluating and Refining Fuzzy Matching Results
Automating Data Cleansing with Alteryx Workflows
In data preparation, one of the common challenges is dealing with records that are similar but not quite identical. This is where Alteryx’s Fuzzy Match tool comes in handy. It allows you to identify entries that are nearly the same, making it ideal for cleaning and standardizing datasets. Whether you’re dealing with slight spelling differences or inconsistent formatting, Fuzzy Match helps consolidate records that actually refer to the same entity, saving time and improving accuracy in your workflows.
What the key benefits of this tool are for businesses
1. Improved Data Quality
Deduplication
It identifies and eliminates duplicate records, even with variations in spelling, typos, or formatting.
Data Cleaning
Businesses often deal with messy data from different sources. The Fuzzy Match tool helps clean data by merging similar entries that should be the same, ensuring a more consistent and reliable dataset.
2. Better Customer Insights
Consolidated Customer Records
Organizations can match customer records that may differ slightly across databases, such as “John Doe” and “Jon Doe.” This enables businesses to have a unified view of their customers.
Enhanced Targeting
By having cleaner and more accurate customer data, businesses can target customers more effectively in their marketing campaigns, leading to higher conversion rates.
3. Streamlined Vendor and Supplier Management
Vendor Consolidation
Similar vendor names across systems (e.g., “ABC Corp” and “A.B.C. Corporation”) can be consolidated, making vendor management more efficient and accurate.
Invoice Matching
Fuzzy matching can help match invoices from different systems where details may be slightly inconsistent, reducing manual effort.
4. Cost Savings
Reduced Manual Work
Fuzzy matching automates tasks that would otherwise require manual review, such as deduplication and data consolidation. This saves time and reduces operational costs.
Improved Decision Making
With cleaner data and better insights, businesses can make more informed decisions, which can positively impact profitability.
Let’s consider a real-world business example
Manufacturing company A is merging with a similar entity, company B, and both have their own master data systems containing vendor and customer information. It’s likely that some vendors or customers are shared between the two companies. This is where the Alteryx Fuzzy Match tool proves useful. To harmonize the data between the two companies, the first step is identifying similar vendors or customers. The challenge arises because vendors from company A and B may have similar, but not identical, names, making it impossible to match them using a standard join method.
In this blog, I will guide you through the steps of using the Fuzzy Match tool, using the example of the case mentioned above.
Step-by-Step Guide: Using Fuzzy Match Tool in Alteryx
Step 1
Prepare the Data in Alteryx
- Load both vendor datasets (for example, Company A and Company B) into Alteryx by using the Input Data tool.
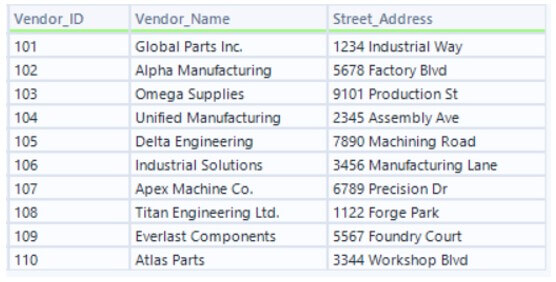
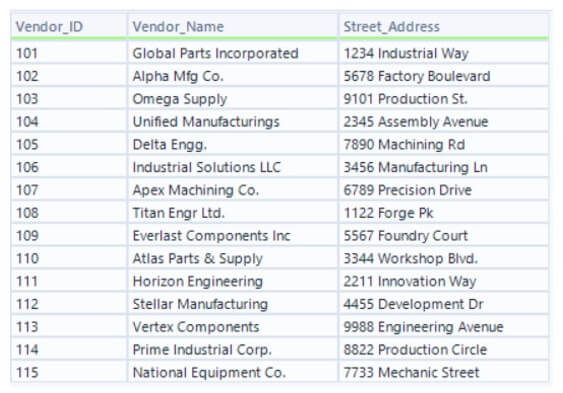
- Each dataset should have similar fields like Vendor_ID, Vendor_Name, and Street_Address.
- In the dataset above, you can see that some Vendor Names have abbreviations as suffixes, while similar ones in the other dataset use full names. Therefore, we can’t perform a natural join on them.
Step 2
Configure the Workflow
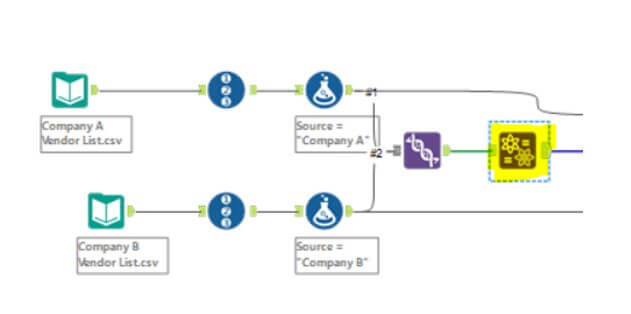
- Drag two Input Data tools onto your workflow and connect them to the datasets.
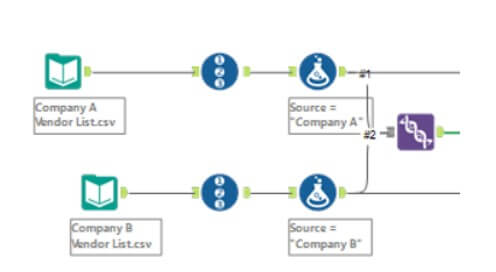
- In case your dataset doesn’t have a unique identifier for each record, you will have to use the Record ID Tool to generate one for each dataset. Also, you will need an identifier to identify the source data. Here I’m using a Formula Tool to create an identifier for each dataset.
Source = “Company A”
Source = “Company B”
- Combine the two datasets using the Union Tool if they are separate files and ensure that they have the same field names for matching.
Step 3
Add the Fuzzy Match Tool
- From the Join tool palette, drag the Fuzzy Match tool onto the canvas.
- Connect the Union data to the Fuzzy Match tool.
Step 4
Set Up Matching Criteria
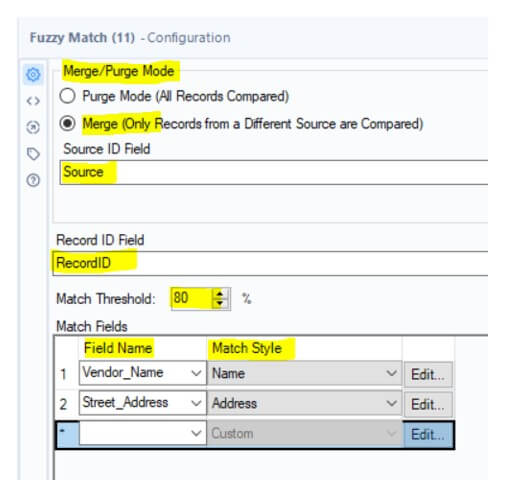
- In the Fuzzy Match Configuration Pane, you will see several options for configuring the matching logic:
- Here, we use ‘Merge Only’ mode since we’re harmonizing two different datasets. If you want to check similar items within one dataset, you will have to use ‘Purge Mode’
- Select the Source ID (Source Identifier) and Record ID field. (Unique Record Identifier)
- Select the Key Field: Choose the field you want to match on (e.g., Vendor_Name). Here we are using two key fields – Vendor Name and Street Address
- Select Matching Style: Choose a matching style based on the data type:
- For Vendor_Name, select Name.
- For Street_Address, select Address.
Step 5
Adjust Matching Threshold
- Set the Match Threshold to determine how similar two values need to be to count as a match. A threshold of 85-90% is usually a good starting point. Here, I’ve set it to 80%.
- Lowering the threshold will allow more flexible matches, but might result in more false positives.

Step 6
Optional: Add More Fields for Matching
- If you want to match by more than just Vendor_Name, you can add fields like Street_Address for additional criteria like I’m doing in this example.
- Use the Weighted Match option to assign more importance to specific fields, e.g., give more weight to Vendor_Name than Street_Address.
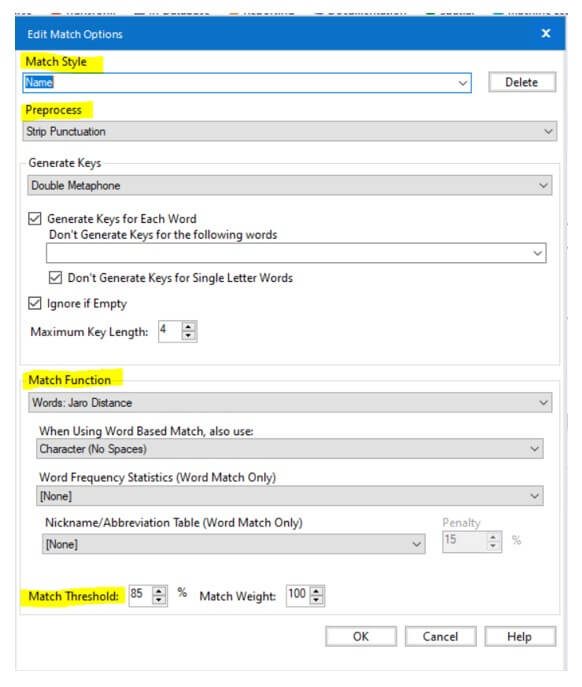
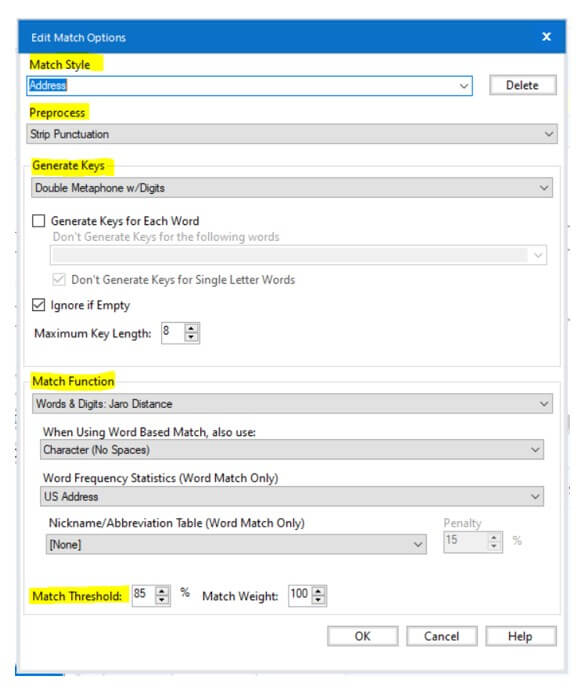
- When you select two fields for field matching, you can always customize the configuration for each field like below screenshot. To perform that, click on edit button next to the match field. Also, you can set individual match threshold as well.
Step 7
Run the Workflow
- After configuring the Fuzzy Match tool, run the workflow by clicking the Run button.
- The output will show potential matches with a confidence score, indicating how similar the records are.
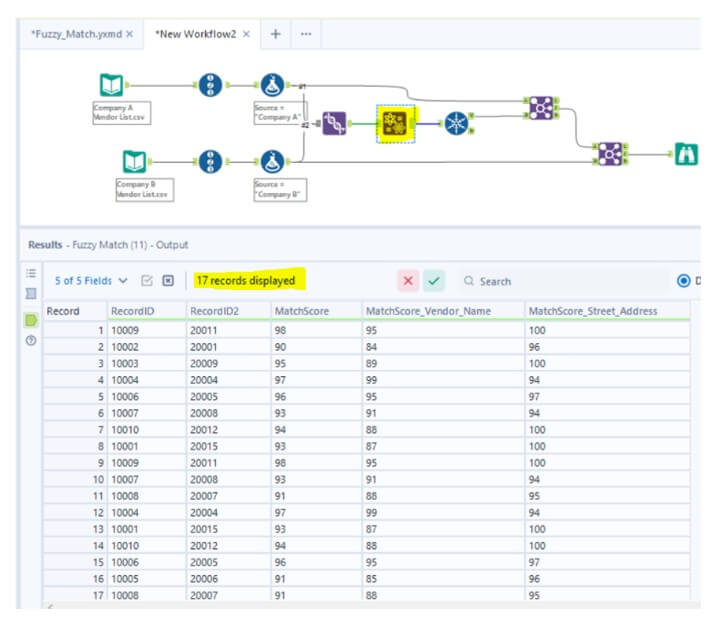
- Here, we find 17 matches, with results including RecordID, RecordID2, Match Score, and match scores for Vendor_Name and Street_Address. This dataset may include duplicates since the Fuzzy Match tool compares records from both datasets. So, in order to eliminate the duplicates, use a Unique tool.
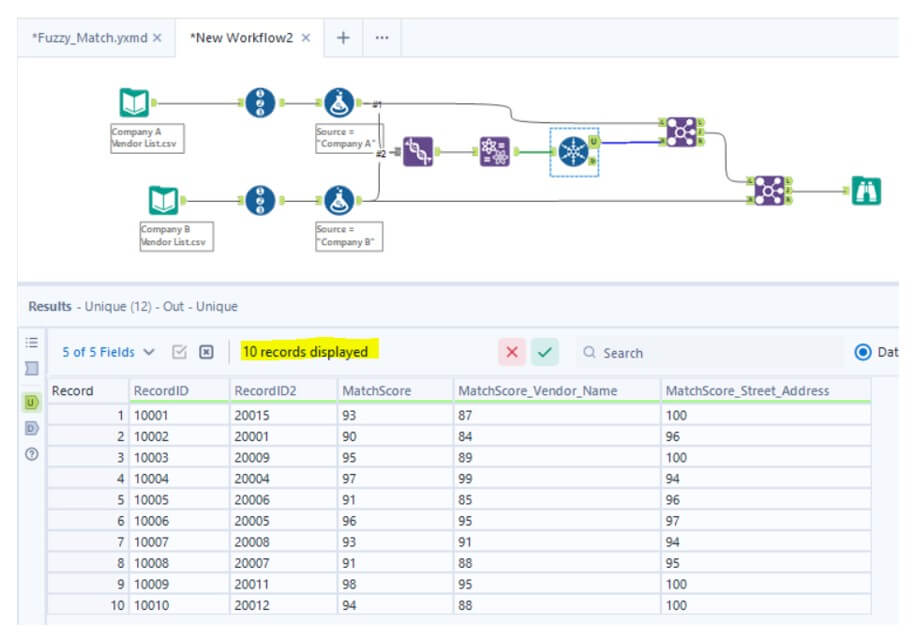
- After the Unique tool, we see the records have been reduced by eliminating duplicates. We have 10 unique records. By looking at RecordID, we won’t be able to understand the respective data values. To view them, we join the Unique tool’s output back with the Company A dataset, then with the Company B dataset, using RecordID and RecordID2 as joining fields.
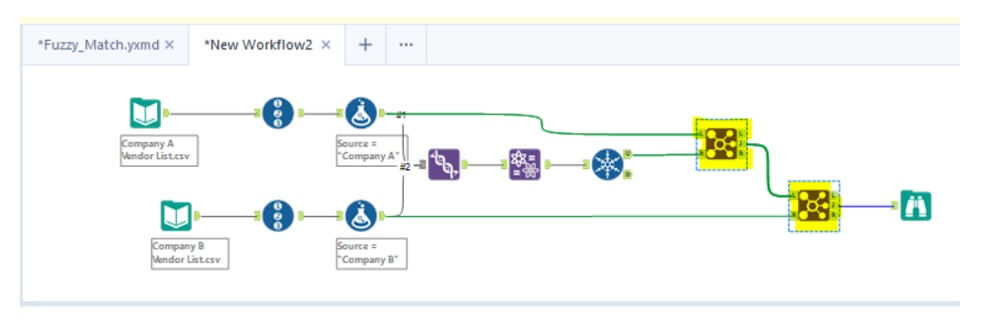
Step 8
Review the Output
- The output from the Fuzzy Match tool includes: (highlighted in yellow is the difference between two dataset records. Therefore, we can identify similar records between the two datasets.
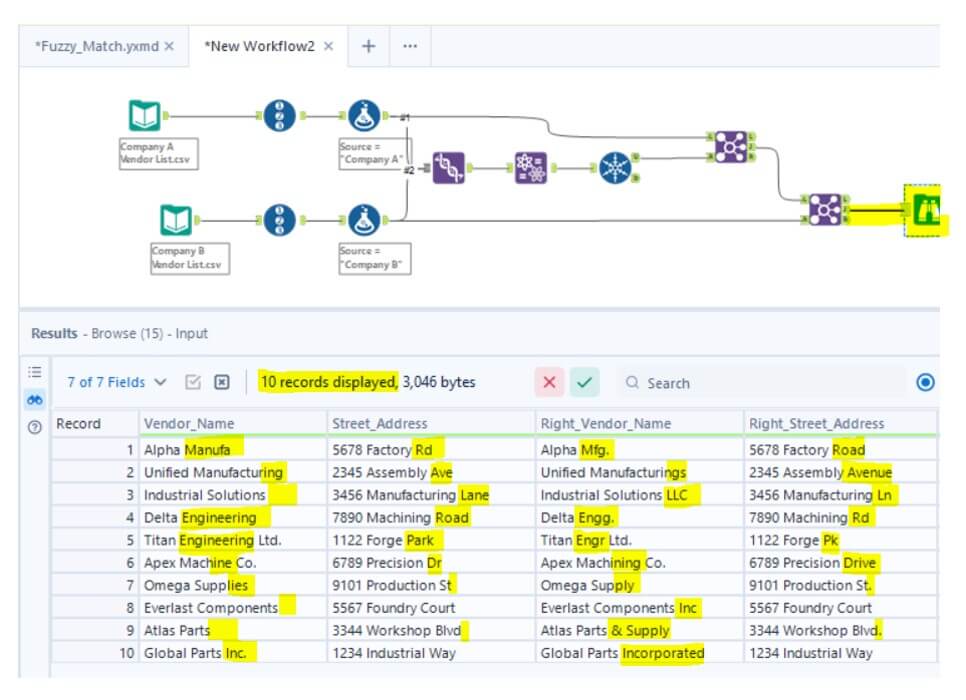
By following these steps, you will be able to harmonize vendor data from two different companies using the Fuzzy Match tool in Alteryx. This process helps ensure consistency across records and minimizes manual data cleaning efforts.
