








 Media Coverage
Media Coverage Press Release
Press ReleaseEnsuring Data Accuracy: Best Practices for Cleaning
Optimizing Data Quality: Effective Cleaning Strategies

In today’s data-driven world, the success or failure of businesses hinges on data. Data has the power to make or break a business. Experiences with inaccurate, duplicate, or unstructured data can lead to poor business processes, subpar customer engagements, poor service delivery, and customer dissatisfaction. So, how do we tackle these issues? The answer lies in understanding and implementing data cleaning.
Understanding the Importance of Data Cleaning
Common Challenges in Data Cleaning Processes
Key Strategies for Effective Data Cleaning
Data Cleaning Techniques for Improved Accuracy
Automation Tools for Streamlined Data Cleaning
Implementing Data Governance for Sustainable Data Quality
Understanding Data Cleaning
Data Cleaning or Data Scrubbing is the process of removing duplicates, correcting inaccurate data, and finding and eliminating errors to improve data consistency and quality. It is a key step in data preparation, that aims to deliver high-quality data when needed.
Data quality issues can arise due to a variety of reasons such as duplications from multiple sources, manual errors during data entry, outdated data, and missing data.
Significance of Data Cleaning
Data Cleaning is important since it improves data quality and helps in making correct decisions by removing incorrect, duplicate, and inconsistent data. This leads to correct information hence saving time for the employees in analyzing or using outdated data. Data issues can also result in harming a company’s reputation.
Data Cleaning Techniques
Remove Irrelevant data
Removing irrelevant data can free up a lot of space. This data can be anything like some numbers, links, or HTML tags. It is best to remove data that have no impact on user analysis.
Remove Duplicates
Duplicate data can be either due to source or by manual mistake while entering. For example, a user entered the wrong phone no. in first attempt and then he entered correct one second time, this will result in two records for same person.
Filter missing Values
It is a critical step during data preparation. You can either filter out the missing values or replace them with something else meaningful e.g. NA, median or mode. This will depend on how much data is missing and how it will affect data.
Eliminate Outliers
Outliers are the extreme cases that are different from most of the data. It is best to remove outliers from data but before eliminating outliers, first identify if they are correct outliers as they can be important for insights. For example, in some data if age is 105, it is rare case and will come as outlier, but it need not be removed from data.
Structure Data Consistently
The data should be consistent across the view or file. For example, ‘Proft & Loss’ should be mentioned in same manner everywhere. It should not be ‘P&L’ at one place and ‘Proft and Loss’ at other. This will affect the accuracy in data visualization.
Standard Data types
Data types should be standard across the files as there can be calculation errors while performing data mining algorithms.
Validate Data
Before sending data for data mining, you should validate data whether it has outliers or not, it gives desired output, is structure okay etc. If there are any doubts or any unexpected output comes up, feel free to go back and check.
Let’s take one use case to understand more about Data Cleaning.
Here is dataset with calories and pulse recorded on different dates (only sample records).
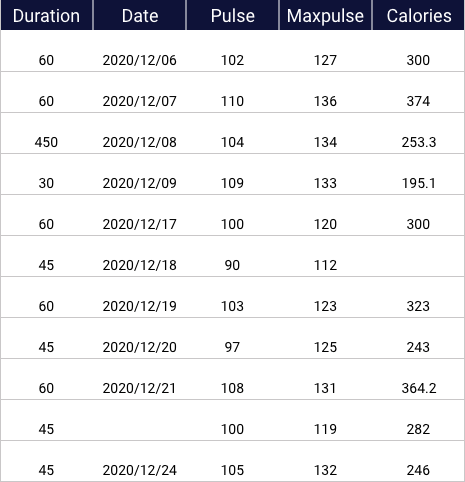
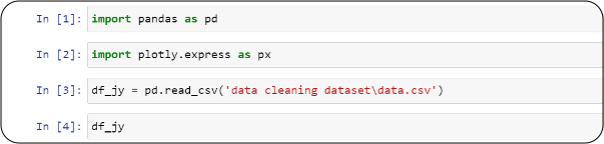
We will use Python code (Pandas) to clean this data.
Let us start with Data cleaning.
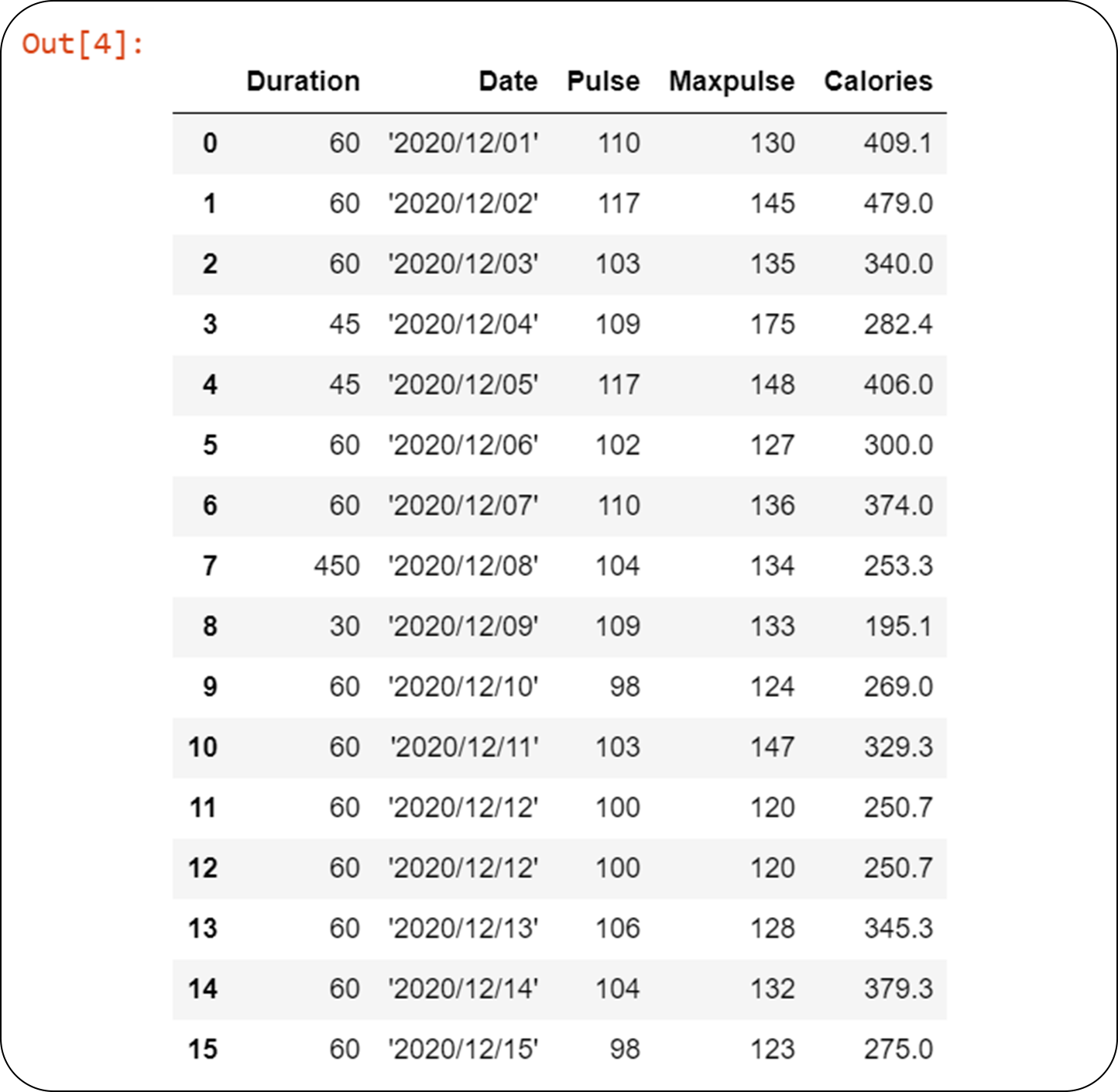
First let’s find out the number of nulls in data.
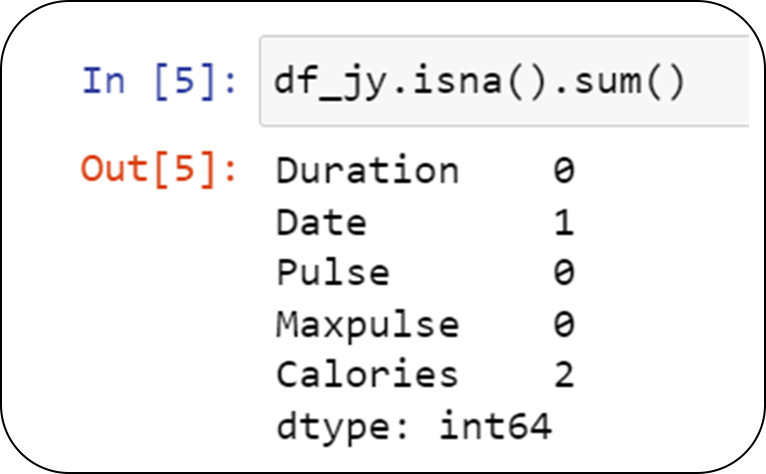
We notice we have nulls in Calories and Date column.
Now let’s find duplicates.
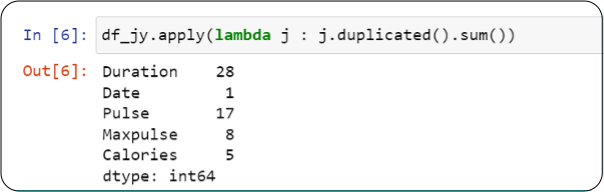
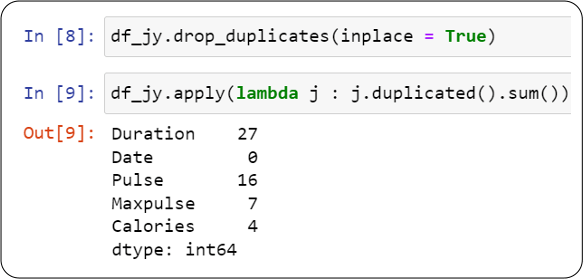
So our first step towards data cleaning would be to remove duplicates.
In order to remove the missing values we can fill nulls in Calories with mean value.
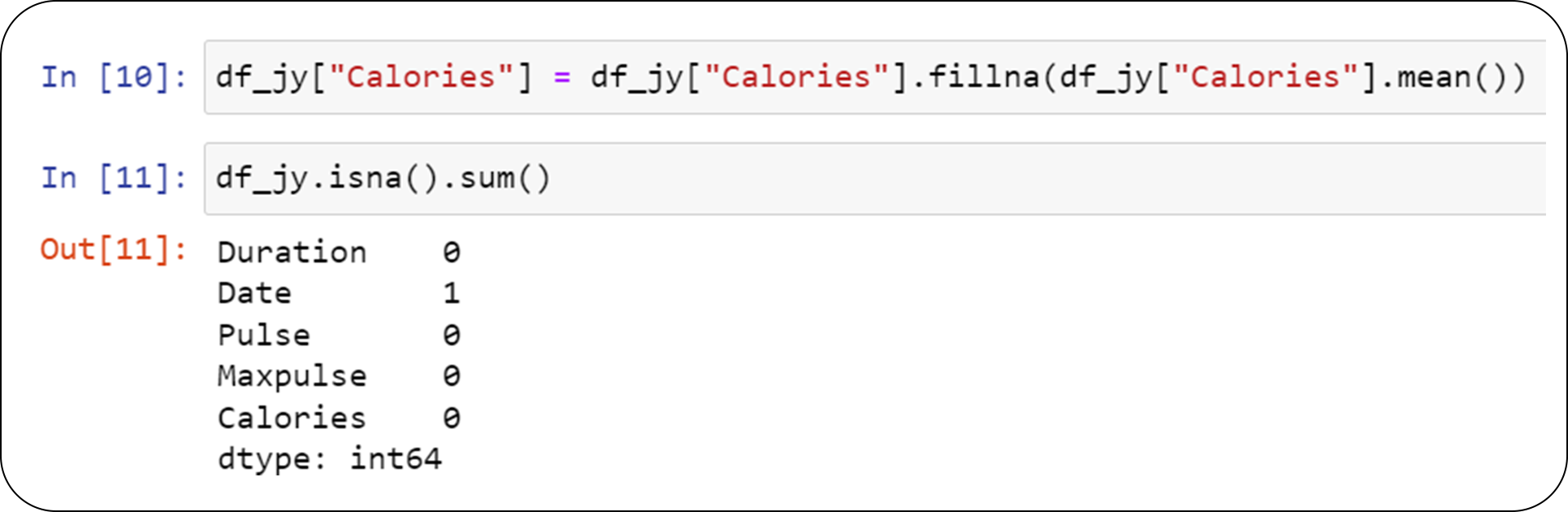
We notice that calories do not have any nulls now.
We can move on to find outliers now
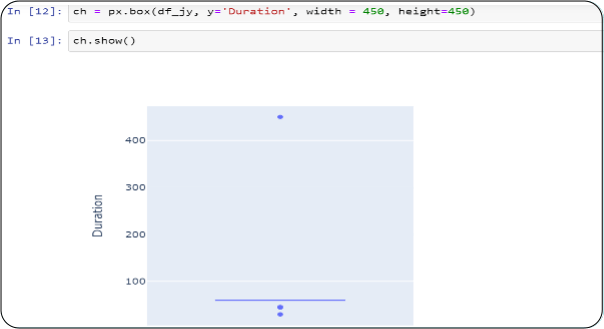
We clearly see, Duration has a value shown as outlier which is 450. It can be a manual error so we can correct it.
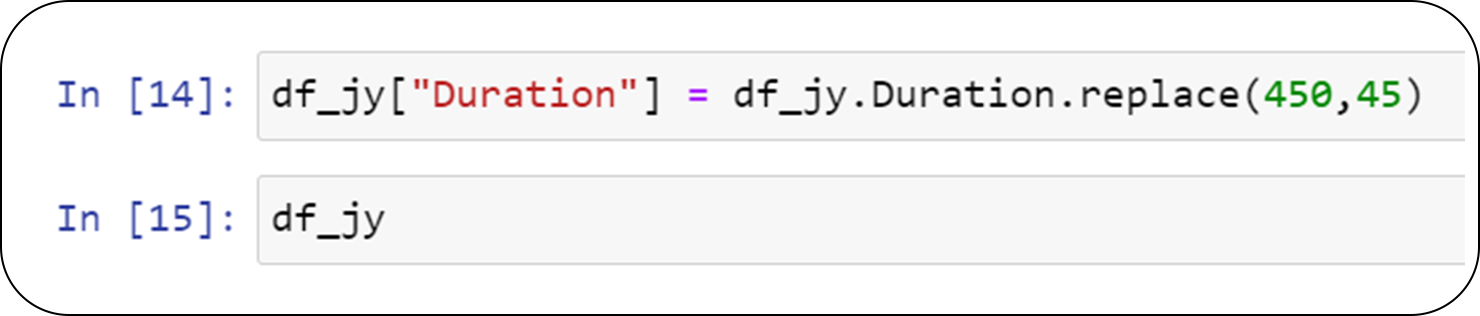
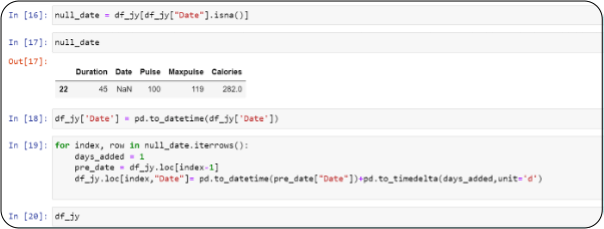
In data we notice, all the dates are in sequence, only one date in missing so we can fill the blank with appropriate date based on previous date.

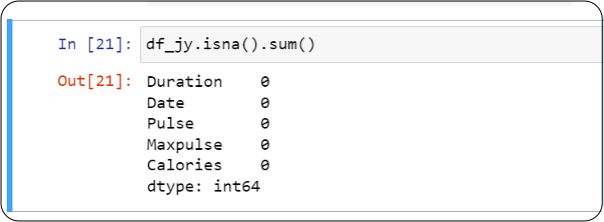
As a last step, we should validate if the steps we have performed are giving expected outcomes or not.
Benefits of Data Cleaning
Better Decision making
High quality data means removing the risk of poor predictions and inconsistent decisions. Business users can make better decisions based on data and get better business outcomes.
Customer Targeting
Good quality data allows businesses to identify their real or potential customers and target them. This reduces the cost of marketing as well.
Increased Productivity
Good data increases productivity as employees do not have to waste time in correcting inaccuracies or analyzing missing data.
Better Outcomes of Machine Learning models
ML models perform better and give better personalized results with clean and high-quality data.
Better Visualization
Good data gives accurate insights and helps in predicting the future data.
Competitive Advantage
Using your data in a creative way or having better data than competitors help to target more customers and predict their personal choices.
Challenges in Data Cleaning
Unorganized Data
There is a high chance that unorganized data cannot be used for analysis in the current form. It must be analyzed and preprocessed before cleaning it.
Scattered Data
Some businesses have scattered data i.e. the data is spread across multiple systems and not present at one place hence making data cleaning a challenging task.
Taking Backup
During data cleaning, duplicate data cannot be completely ignored. Back up is an important process for companies to protect data in case of malicious attacks. If backup is affected during data cleaning, it can be an issue.
Variety of Data
A business usually has multiple formats of data like excel, text file, videos etc. Cleaning one kind of data could be different from another kind. This can be a time-consuming process.
Conclusion
Data Cleaning is a fundamental step for every business. Analyzing and using unstructured data yields no benefits. Although it is the most time-consuming part of the job, data cleaning significantly influences business decisions, making it an indispensable process.
