








 Media Coverage
Media Coverage Press Release
Press ReleaseEfficient Data Cleaning with Python Libraries
Techniques to Transform Messy Data into Actionable Insights
Enhancing Data Accuracy with Python
Why Data Cleaning is Critical for Accurate Insights
Top Python Libraries for Data Cleaning and Preprocessing
Step-by-Step Guide to Effective Data Cleaning in Python
Common Data Cleaning Challenges and How to Overcome Them
Handling Missing Values with Python
Removing Duplicates and Irrelevant Data
Transforming Data for Analysis Using Pandas
Automating Data Cleaning Processes
Data Cleaning, also known as data cleansing, is the process of identifying and removing bad data, i.e., checking for null values, inconsistent data, and duplicate data.
Data Cleaning is one of the crucial steps we need to follow as a data engineer. We are provided with raw data, which means the original form of data from its source. Attempting to visualize that data directly may cause ineffective or unclean results. Therefore, before proceeding with any analysis or visualization, we need to follow data cleaning.
Python offers various libraries that can be used for the data cleaning process. Among these are two libraries that stand out for their ease of use and familiarity. These are:
- Pandas: Pandas is one of the most widely used libraries in Python, used for data manipulation. It has various functions suitable for data analysis.
- NumPy: NumPy is an essential library in Python, offering functions for working with multidimensional arrays. When combined with Pandas, NumPy provides additional functionalities to enhance data cleaning.
Data Cleaning Best Practices
Let’s look at some essential best practices and key steps for Data Cleaning.
Step 1
Understand the Data
Understand the structure of the data, its formats (like CSV, JSON, etc.), and datatypes. Ex: Considered CSV dataset and checking data
Consider one Dataframe and define the path
data = pd. read_csv("File_Path")
To check the list of columns
data.columns
Basic information about the Dataframe
data.info ()
To display the first 5 rows
data.head()Step 2
Documenting Process
Based on the data, understand the necessary steps and make a list to implement easily.
Step 3
Handling Missing Values
Check if raw data contains any null or missing values and handle them using appropriate techniques.
To check the null value count column-wise
data. isnull().sum()
Dropping null values
data.dropna(inplace=True)Step 4
Remove Duplicates
Identify and remove duplicates to maintain accuracy.
Ex: Checking for Duplicates.
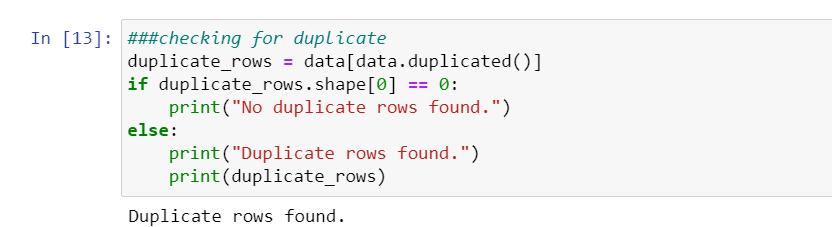
Dropping those duplicates
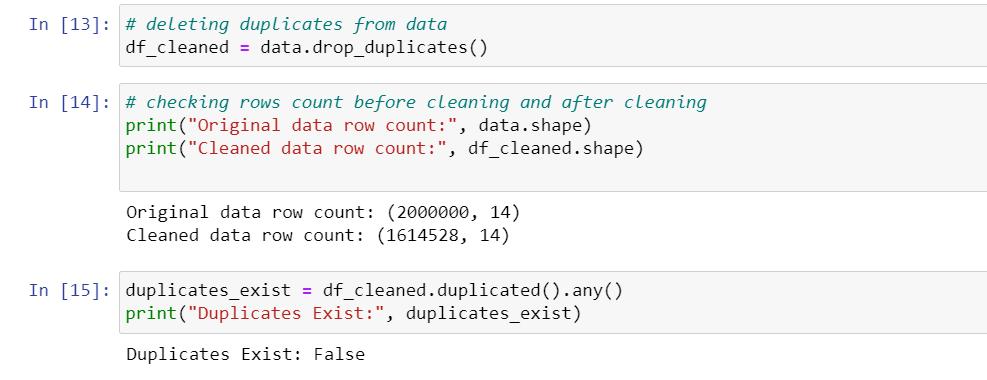
Step 5
Standardize Date Formats
If there are date or measurement-related fields, ensure they maintain a standard format.
Ex: considered order date column
After changing the date format:
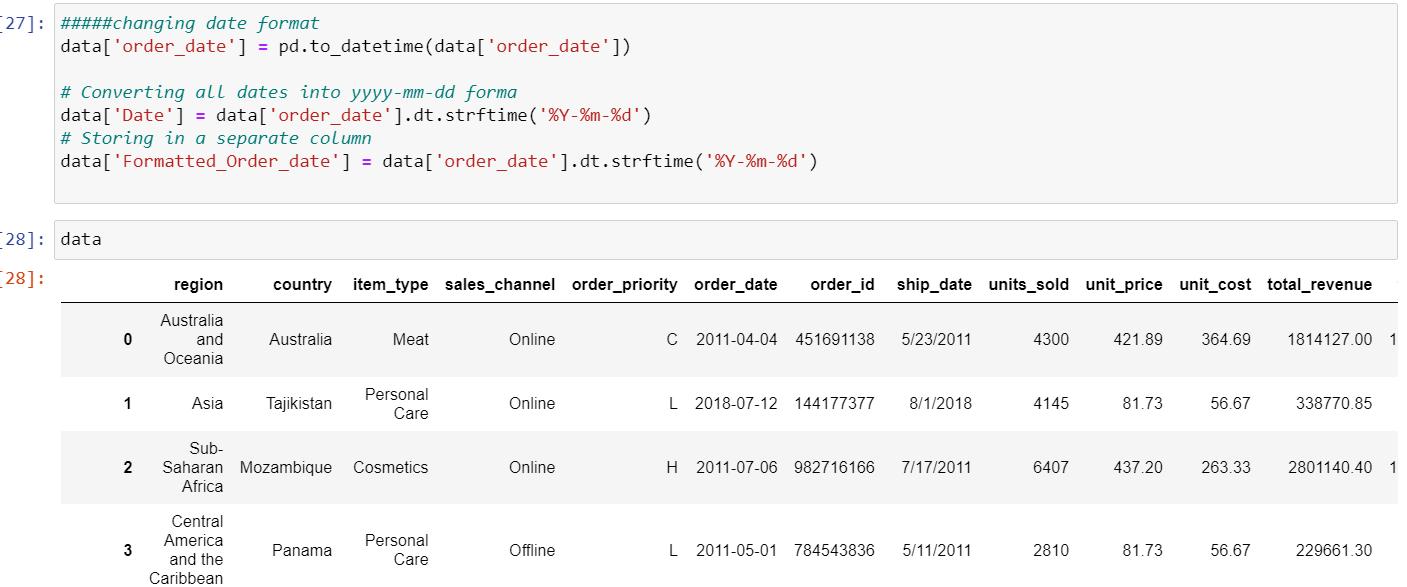
Step 6
Test the data
After following the necessary steps, test the results and validate them to ensure they work as expected and provide accurate results.
Step 7
Document Cleaning Process
Post-completion of all these steps, documenting the process would be very helpful for further analysis and decision-making.
Execution Process:
Advantages Of Data Cleaning Using Python
- Ease of Use: Python has built-in libraries that are easy to use, often requiring minimal code to perform tasks.
- Effectiveness: Python is highly effective in performance, and it’s open-source and free to use, making it a cost-effective choice for data cleaning tasks. Additionally, Python’s scalability and efficiency can help reduce computational costs when processing large volumes of data.
- Scalability: Python’s scalability makes it suitable for handling both small and large datasets.
- Data Exploration: Python supports various tools for interactive data exploration, including Jupyter notebooks and visualization libraries like Matplotlib and Seaborn.
By following these steps, we can ensure that the process provides accuracy in data analysis, helping us gain knowledge and practice on different datasets to improve our data cleaning skills.
