








 Media Coverage
Media Coverage Press Release
Press ReleaseIntroduction to Scala for Big Data: Part I
Scala Programming Basics: Getting Started with Big Data
Exploring Scala for Data Science: An Introductory Guide
Over the past several years, the Scala programming language has seen a meteoric rise in use among software engineers, data scientists, and business intelligence analysts across many industries. Scala is a general-purpose programming language that compiles on the Java Virtual Machine (JVM) in the same manner that Java files are compiled.
Scala provides added flexibility by supporting functional programming and imperative programming commonly used by Data Scientists in addition to object-oriented programming (OOP). To get started on Scala programming and syntax, use this tutorial for guidance on the fundamentals of the language.
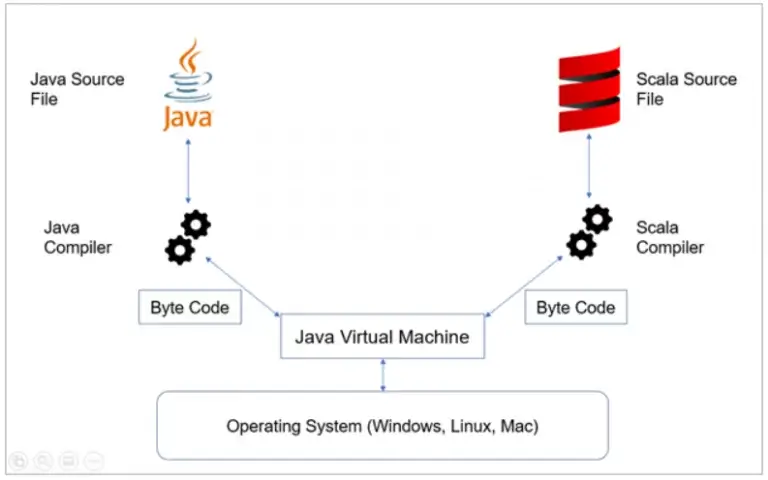
In addition to Scala, Spark is a big data technology written in Scala that manages Hadoop clusters. It’s an application framework that operates on a storage system for in-memory data processing. Besides, it is a compute engine that allows users to run batch or streaming jobs on a cluster–usually the Hadoop Distributed File System (HDFS), Cassandra, or AWS S3. Take a look at this overview of Hadoop for more information.
Understanding the Fundamentals of Scala Programming Language
Introduction to Scala’s Role in Big Data Processing
Getting Started with Scala: A Beginner’s Guide
Exploring Scala’s Applications in Data Science and Big Data
The primary mode of working with big data in Spark is using a distributed collection of data organized in rows and columns stored in memory called a DataFrame. DataFrame functions like a table, but with a user-defined schema on the data read (rather than on the write as is standard for RDBMS). DataFrames can be read from formats such as CSV, Parquet, JSON, and tables stored in Hive. In the next installment of the Scala for Big Data series, we will discuss some of the basics of working with Spark DataFrames using the Scala programming language.
Scala Essentials: Key Concepts and Syntax Basics
Leveraging Scala for Big Data Applications: A Comprehensive Overview
Scala Programming for Data Scientists: An Introduction to Essential Tools and Techniques
Practical Examples of Scala in Action: Real-world Use Cases and Applications
In this article, I will assume that you have your Hadoop and Spark environment already created. However, if you have not yet configured it, you should first set up Ubuntu on your virtual machine as described here. Then refer to this article for Hadoop setup and this article for Spark setup.
The goal we hope to achieve in this series is to create a basic analytics project using linear regressions with Scala in Spark to analyze two major economic indicators from the US Federal Reserve Bank, the Unemployment Rate and the Case-Shiller Housing Index. We will also download a CSV file of historical S&P 500 data from Yahoo finance here.
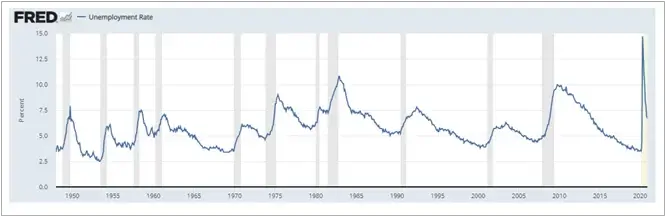
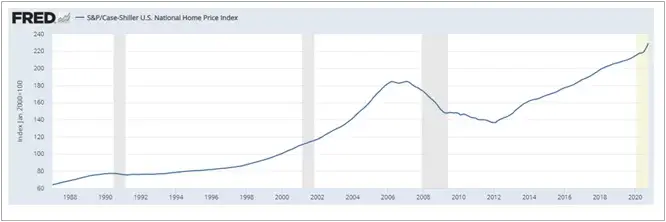
In the next article, we will discuss uploading this data to the Hadoop cluster and performing some data manipulation using Scala in Spark to standardize the data we have sourced from the internet.