Unlocking the Secrets of Machine Language Evolution
The Future of Natural Language Processing: GPT-4 and Beyond
Imagine you walk into a bustling marketplace with a swirl of languages around you. Merchants hawking their wares, children giggling, and perhaps the sound of a quarrel taking place nearby. To someone like us, a human, most if not every sound, makes sense. However, for a computer, this vibrant scene is just a jumble of soundwaves, devoid of any real meaning. This is where Natural Language Processing (NLP) comes in – it’s the bridge between the human symphony of words and the cold logic of machines.
At the heart of modern NLP lies a powerful architecture called the Transformer. Think of it as a masterful translator, unravelling the nuances of human language with accuracy. But before Transformers arrived on the scene, understanding the human language for machines was driving a car through a dense fog. Words were mere numbers, devoid of context, like alphabet soup with no recipe.
Understanding the Early Developments in Machine Language Models
Challenges and Triumphs: The Advancements in GPT-4
Future Trajectories: Possibilities and Innovations in Natural Language Processing
The Impact of Machine Language on Artificial Intelligence and Communication
From Word Embeddings to Transformers

Early pioneers in NLP realized that to understand language, machines needed a way to grasp the relationships between words. Enter Word Embeddings – algorithms that assign unique vectors to each word, revealing hidden connections. Similar words, like “king” and “queen,” reside close together in this semantic map, while opposites like “hot” and “cold” drift to opposite corners. This was the first step in giving machines a sense of direction in the vast jungle of language.
RNNs – Cautious First Steps
Moving beyond static maps, Recurrent Neural Networks (RNNs) emerged as the next big thing. Imagine them like conveyor belts, processing words one by one, carrying some information from the past. They could handle sequences like sentences, a vast improvement over static embeddings. However, RNNs had a memory flaw – they tended to forget the early words on long sentences, like losing your favorite toy at the start of a winding parade.
LSTMs – Memory Champions with Gates
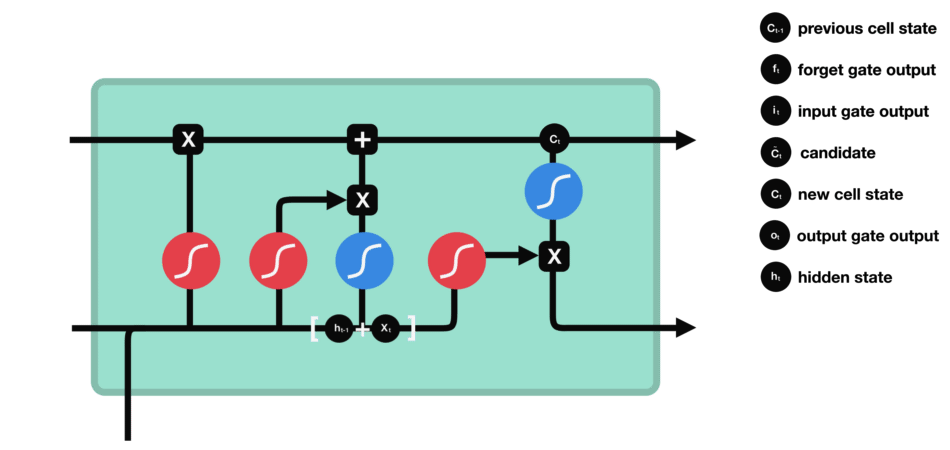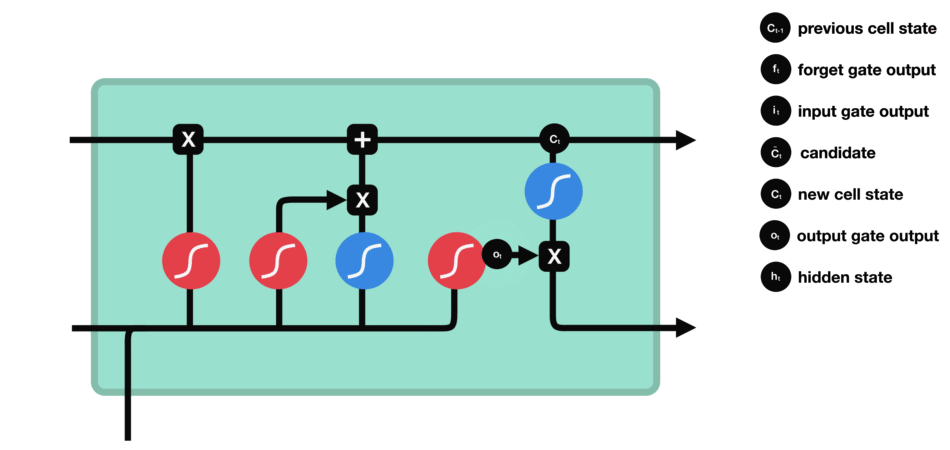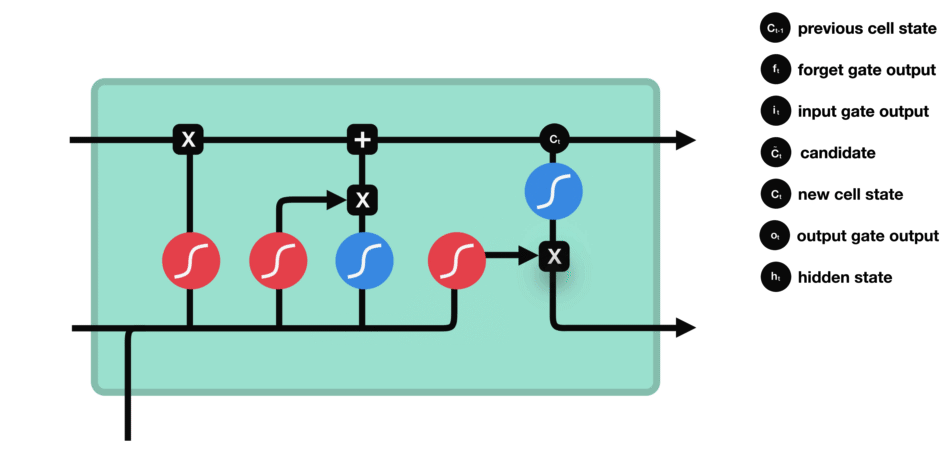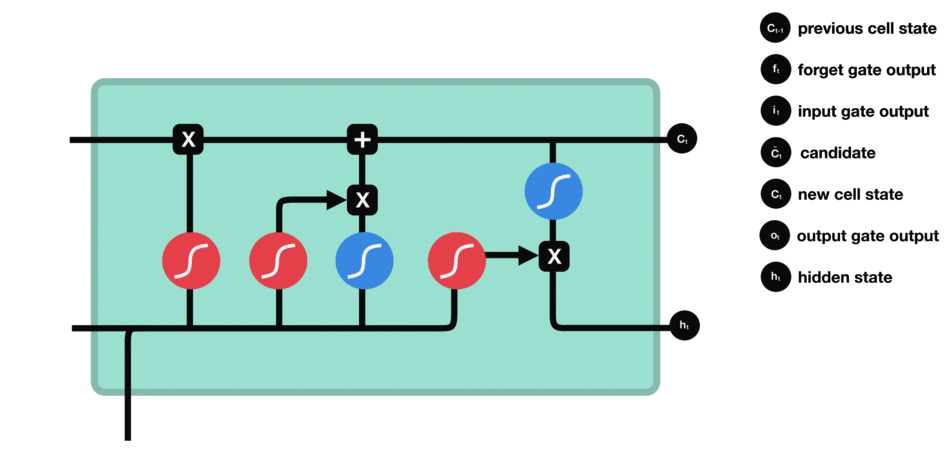
Fortunately, the story doesn’t end with forgetful machines. Enter Long Short-Term Memory (LSTM) networks, the memory champions of NLP. Think of them as adding “gates” to the conveyor belt, selectively allowing important information to stay while letting go of irrelevant details. This made LSTMs capable of understanding much longer and complex sentences, akin to remembering the entire parade route and spotting your precious toy even at the end.
Attention – The Game Changer
Then came the game-changer: Attention. Imagine each word having a spotlight – Attention lets these spotlights shine brighter based on their relevance to the whole sentence, not just their order. This was revolutionary, especially for translation tasks, where context is king. No longer were machines locked in a linear procession of words – they could finally grasp the connections and nuances that make language truly meaningful.
Transformers – The Masterminds Behind Language Models
Transformers built upon these breakthroughs, combining Attention with other ingenious tricks. They’re like the architects of modern language models (LLMs) like GPT-4, which go beyond mere understanding to generating natural language itself. It’s like training a master storyteller with a library of books, letting them weave their own tales based on the patterns and relationships they’ve learned.
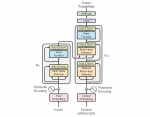
But before we talk about GPT and its subsequent avatars, it’s only fair that we go over transformer elements in detail and understand how each module works.
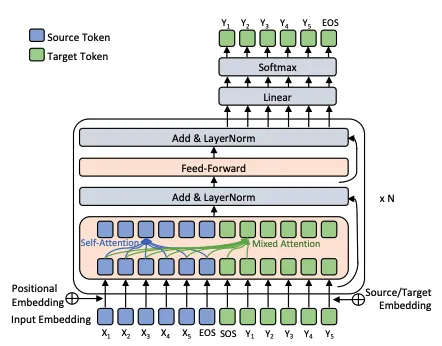
- Input Embedding and Positional Encoding: The Transformer begins by converting words into vectors, similar to Word2Vec. Positional encodings are then added, providing context about a word’s position in a sentence. This step ensures that the word ‘bank’ in “river bank” and “money bank” are differentiated not just by their inherent meaning but also by their contextual placement.
- Multi-Headed Self Attention: This is where the “Attention” or “co-relation” and “contextualization” mechanism comes in. This is the heart of the Transformer model — multi-headed self-attention mechanism. It allows each word to interact with every other word in a sentence, weighing the relevance of each and creating a context-rich representation. Think a group discussion where each word “listens” to the other and adjusts its “understanding” based on the “importance” of its contribution.
- Encoder-Decoder Architecture: Transformers follows an encoder-decoder structure. The encoder listens carefully encoding the input into a rich tapestry of meaning, creating context and relationships. Then, the decoder steps in to craft a response with accuracy. But even the most eloquent speakers need some sort of grounding and here’s where “Add and Norm” (the Balancer) steps in, stabilizing the flow of information, ensuring clarity and coherence. Next, the feed-forward network acts as a bridge, distilling the essence of the message into a form the decoder can easily grasp. Finally, the decoder uses the processed information to generate the output. This step is where the Transformer’s power culminates into coherent and contextually relevant output.
This remarkable process, powered by the Transformer architecture, is still evolving. Modern variants like GPT (Generative Pretrained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) have built on this architecture, pushing the envelope for specific tasks like language generation and understanding.
GPT-1 – Rise of Storytellers
GPTs or Generative Pre-trained Transformers of today are nothing but upstart offsprings of Transformers. From GPT-1’s inception in 2018 to GPT-4’s groundbreaking advancements these models have revolutionized the way machines understand and generate human language.
Imagine pouring something like the contents of the biggest library in the world into a single machine, and letting it absorb every story, poem, and scientific text ever written. That’s the essence of pre-training, a technique used in GPT and its siblings. GPT-1 was the first of the line, becoming a skilled storyteller. It crafted creative text formats like poems and code, using its massive internal library as inspiration.
GPT-2 – LLMs Come of Age
Expanding Horizons in February 2019, GPT-2 emerged, retaining the foundational architecture of GPT-1 but with a sizeable increase in size and capacity. GPT-2’s architecture, slightly different from GPT-1, was a bit of a leap of faith, relying more on pre-training than fine-tuning. This shift meant GPT-2 could generalize across tasks without specific training, a significant advancement in AI.
GPT-3 – The Wise Elder
GPT’s next advancement came in June 2020 with the advent of GPT-3, a behemoth with 175 billion parameters (or brain cells). Unlike its predecessors, GPT-3 could handle various tasks with minimal input, showcasing its few-shot learning capabilities. Its size and training on diverse data allowed it to generate astonishingly human-like text.
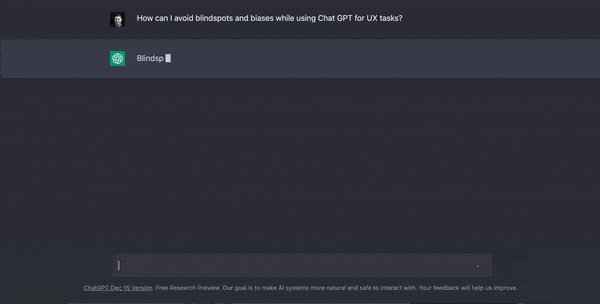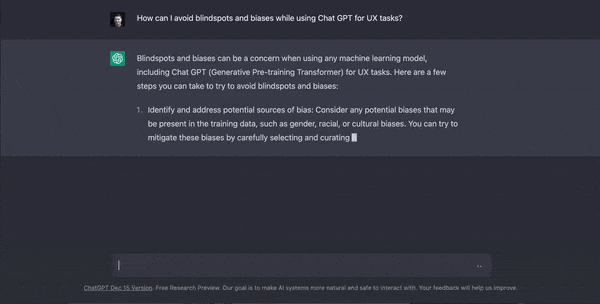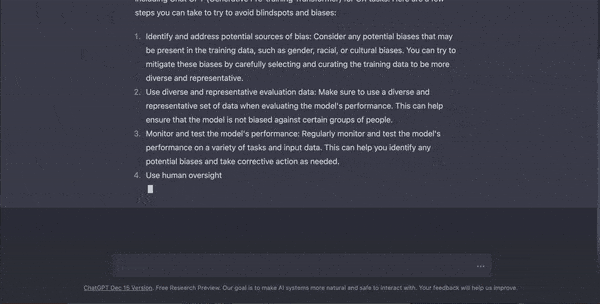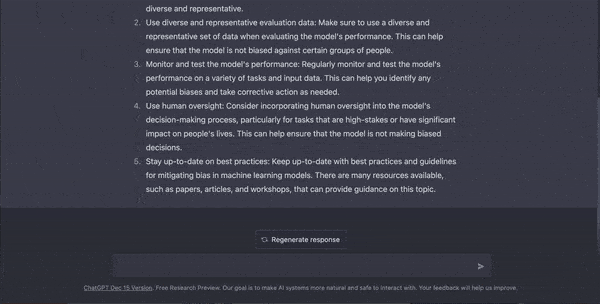
GPT-4 – The Multimodal Mastermind
In 2023, the GPT’s present chapter unfolded with GPT-4, the pinnacle of LLMs. This model is not just a master of words – it can also understand and generate images, making it truly multimodal. Despite its similar architectural roots, GPT-4 shows significant advancements in understanding and generating text, surpassing previous models in various professional and academic benchmarks.
The Journey from Word Soup: Early Insights into Machine Language Development
GPT-4 Unveiled: Breaking Down the Features and Capabilities
Overcoming Challenges: The Roadmap to Future Natural Language Processing
Revolutionizing Communication: The Intersection of AI and Language Models
Future of Language Models Beyond GPT
But the story of language models doesn’t end with GPT-4. Researchers are already pushing the boundaries further, exploring new frontiers in communication between humans and machines.
GPT-4 Turbo – The Master Storyteller
GPT-4 Turbo, an advanced version of GPT-4, offers significant enhancements including a vast 128K context window capable of handling over 300 pages of text in a single prompt. It excels in tasks requiring precise instruction-following and format generation, such as XML responses, and introduces a new JSON mode for valid JSON outputs. Additionally, the ‘seed’ parameter in GPT-4 Turbo enables reproducible outputs, crucial for debugging and unit testing. Soon, it will also provide log probabilities for output tokens, aiding in features like autocomplete. GPT-4 Turbo is like a master storyteller with its own memory palace!
Chain of Thought Reasoning
Another exciting development is “Chain of Thought” reasoning, a technique that helps models break down complex tasks into logical steps, making their problem-solving more transparent and reliable. Additionally, the “Medprompt” technique combines CoT reasoning with other techniques, enabling GPT-4 to excel in tasks across various domains, including medical knowledge. Researchers have also developed strategies like dynamic few-shot selection and choice shuffle ensembling, enhancing GPT models’ adaptability and accuracy.
The Evolution Continues
The journey of how machines learned to talk – from word soup to natural language – has been nothing short of remarkable. Transformers were just the beginning; the future of NLP holds immense possibilities. As we marvel at these advancements, we also look forward to future innovations that will continue to redefine our interactions with technology. The story of GPT models is far from over; it’s a narrative of relentless progression, and we’re just witnessing the beginning.
