








 Media Coverage
Media Coverage Press Release
Press ReleaseOptimizing Informatica and Oracle Integration
Best Practices for Informatica Performance Tuning
USEReady’s Tips for Maximizing Oracle Efficiency
ETL (Extract, Transform, Load) tools like Informatica are real workhorses for data integration and quality management. Enterprises have long come to rely on Informatica for smooth flow of information. But what if you could squeeze even more efficiency out of this powerful tool? There are several ways in which you can maximize Informatica’s performance while interacting with the Oracle database. These methods can speed up data processing, reduce errors, and ultimately increase the efficiency of data integration techniques.
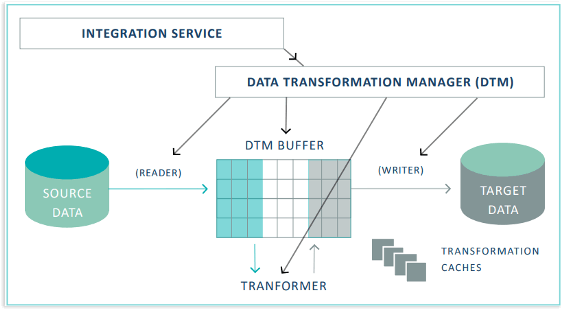
Introduction to Informatica and Oracle Optimization
Key Strategies for Enhancing Performance
Best Practices for Data Integration Efficiency
Troubleshooting Common Performance Issues in Information
Overview of Informatica-Oracle Integration
Database Optimization Techniques
Tools for Monitoring and Tuning Performance
Case Studies of Successful Optimization
In this blog, we will look at some of the ways to fine-tune your Informatica workflows and unleash peak performance. We’ll explore strategies that leverage the strengths of both Informatica and Oracle, ultimately leading to faster data processing, reduced errors, and a streamlined workflow. Read on.
- Indexing: Making indexes on the columns that are commonly used in joins and where conditions might greatly enhance query performance is one of the most efficient approaches to increase efficiency. Oracle can locate and retrieve relevant information more rapidly thanks to indexes, which cuts down on overall processing time.
- Partitioning: Oracle performance can also be enhanced by partitioning a table, particularly for large ones. Partitioning facilitates the division of data into more manageable, smaller pieces that can be processed more quickly.
- Pre-session SQL: Before Informatica fetches the data, we can apply any required transformations or filters directly in the database by using the pre-session SQL option in Informatica. This can enhance overall performance by lowering the volume of data that Informatica must process.
- Bulk Load: Informatica’s bulk load features allow us to more effectively load massive amounts of data into Oracle databases. Writing data in bigger batches as opposed to row-per-row is known as bulk loading, and it can shorten overall processing times.
- Maintain Statistics: Maintaining current database statistics is crucial to maximizing Oracle query performance. Make sure Oracle’s query optimizer can make the best choices possible when running queries by routinely analyzing and collecting statistics on tables and indexes.
- Use Optimized SQL: With Informatica, we can concentrate on writing SQL queries that are designed for efficiently retrieving and manipulating data from Oracle databases. Refrain from adding pointless filters, joins, and transformations as these can cause query execution to lag.
Mapping Optimization
To increase the performance, we can analyze the mapping and perform below steps:
- Reduce Transformations: Try to keep the mapping’s transformation count as low as possible. When transferring data, each transformation adds overhead. Performance improves with fewer conversions.
- Shared Memory: Increase the amount of shared memory (between 12 and 40 MB) for mappings that encounter a lot of transformations to increase efficiency.
- Calculate Once: Avoid redundant calculations or tests. Calculate values once in expressions and use flags to optimize performance.
- Minimize Data Movement: Eliminate unnecessary links between transformations. As a result, less data is transferred. Additionally, think about implementing active transformations early in the mapping, such as aggregators and filters.
- Watch Data Types: Consider the conversions of data types. Preparing data flow in advance will help minimize changes during transformations.
- Reuse Transformations: Plan for reusable transformations. To increase efficiency, use ports as variables in addition to mapping variables.
- Mapplets: Mapplets can be utilized to encapsulate numerous reusable transformations. They minimize errors and help leverage important work.
Lookup Optimization
We can optimize our lookup transformation and enhance performance in below ways:
- Use the ‘Cached Lookup’ transformation instead of the ‘Unconnected Lookup’ transformation when possible. Because Unconnected Lookup is slower as it uses the database each time it queries the table, while Cached Lookup stores the lookup table in memory.
- Use the ‘Persistent Cache’ option in the lookup transformation to store the lookup data in a persistent cache file. By avoiding reloading the lookup data from the database each time the transformation runs, performance can be improved.
- The number of columns in the lookup condition should be limited to those that are essential to matching the lookup data. This can reduce the amount of data that needs to be processed and hence performance can be improved.
- Optimize the lookup performance in the database by using indexes on the lookup columns. Incorporate indexes into columns that are frequently used in the lookup condition.
- In the lookup transformation, select ‘Sorted Input’ to sort the input data on the lookup columns. This can improve performance by allowing the lookup transformation to use binary search to find the matching rows.
- To optimize the lookup query, use the ‘Lookup Override’ option. Filter the data before it is fetched from the database by adding WHERE criteria to the SELECT statement and specifying only the necessary fields.
- For best results, arrange the lookup conditions as follows:
Equal to (=)
Less than (<), greater than (>), less than or equal to (<=), greater than or equal to (>=)
Not equal to (!=) - Optimize Multiple Lookups: If the mapping calls for several lookups, carefully consider how to execute them properly.
Expression optimization
- Use of aggregate functions: Instead of manually computing values in expressions, use aggregate functions like SUM, AVG, COUNT, etc.
- Use parameters and variables: To maximize efficiency, keep intermediate results in parameters and variables so you can utilize them again in different expressions.
- Use reusable expressions: To save redundancy and boost efficiency, create reusable expressions and store them in a separate transformation.
- When checking many conditions, it is preferable to use an IIF expression.
Pushdown Optimization
Enabling Informatica’s pushdown optimization to send processing tasks to the Oracle database whenever it is possible is another technique to boost performance. Oracle can now fully utilize its processing power and capabilities, which leads to better performance and faster query execution. Pushdown Optimization in Informatica Cloud facilitates database-level data processing, which is significantly quicker and more effective than Informatica data processing. There are different types of pushdown optimization which can be used:
- Source-side Pushdown Optimization: A feature known as “source-side pushdown optimization” allows data processing to be pushed down to the source database, negating the need to move the data into Informatica for transformation and processing. This could lead to a significant boost in network throughput and a reduction in the amount of data transmitted. It does the transformations and filtering at the source itself by pushing down the processing to the source database, before loading the data into Informatica for further processing or loading into the target database. This makes use of the source database’s strength and capabilities, particularly its SQL processing and operation skills. The data integration process operates more efficiently overall and makes the most use of its resources thanks to optimization. In this instance, the Data Integration Service creates and runs a SELECT query based on the transformation logic for every transformation it can submit to the database.
- Target-side Pushdown Optimization: The target database is pushed with as much processing logic as is practical using a performance optimization technique called “target-side pushdown optimization” in Informatica. The performance of data integration processes can be significantly improved by reducing the amount of data transferred between the source and target systems and making use of the destination database’s processing power for complex transformations. By implementing target-side pushdown optimization, Informatica may generate SQL queries with the necessary transformation logic and send them down to the target database for execution. This could result in shorter execution times, reduced network traffic, and overall improved performance of the data integration process. Depending on the transformation logic, the Data Integration Service generates an INSERT, DELETE, or UPDATE statement for each transformation it can do.
- Full Pushdown Optimization: The data integration tool Informatica PowerCenter has a function called full pushdown optimization that maximizes the efficiency of data transformations by pushing as much of the processing logic as is feasible. This reduces the amount of data that the ETL tool needs to process, enabling faster data integration processes. Informatica can take advantage of the built-in capabilities of the database to improve performance by using SQL language particular to the database.
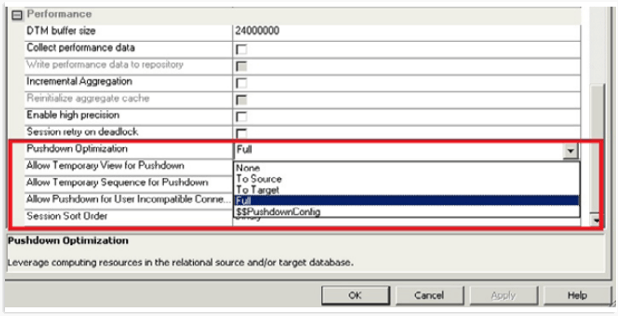
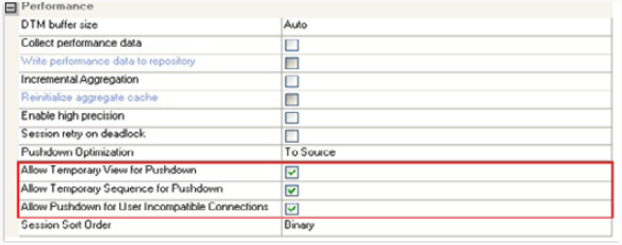
The performance and effectiveness of data integration procedures can be improved by putting these Oracle optimization strategies into practice in Informatica. By using these strategies, you may shorten processing times, enhance query speed, and ultimately streamline the workflow for data integration.
Conclusion
Thorough comprehension of the data, the ability to fine-tune SQL queries, and ongoing performance monitoring are essential to optimizing Oracle databases for Informatica. We can greatly increase the effectiveness and speed of our ETL procedures by putting these tactics into practice. By using these methods, Informatica workflows will be guaranteed to not only meet but also surpass performance standards, giving businesses access to real and quick data processing capability.
