Data Algorithms: Harnessing Real-Time Insights from Large Volumes of Data
Generating Real-Time Insights: The Power of Data Algorithms in Large-Scale Analysis
Optimizing Data Processing: Strategies for Leveraging Algorithms in Real-Time Analytics
Organizations realize the value of data since it enables them in making critical decisions. The volume and velocity at which data generated poses huge challenge for organizations to use the data effectively and make effective interpretation.
According to Forrester Research, merely 12% of enterprise data is used to make decisions today. Also, less than 0.5% of human generated data (through digital platforms) is used in analysis. IDC forecasts the growth in IoT connected devices is expected to generate 79.4 Zeta Bytes (ZB) of data across 41.6 billion devices, which makes it further worse.
Understanding Data Algorithms: Key Concepts and Techniques for Real-Time Insight Generation
Implementing Data Algorithms: Best Practices for Processing Large Volumes of Data in Real-Time
Real-Time Analytics with Data Algorithms: Enhancing Decision-Making with Dynamic Insight Generation
Optimization Strategies: Maximizing Efficiency in Real-Time Data Processing with Algorithms
Data Algorithms provide useful techniques to handle Big Data Analytics efficiently. One such scenario is dealing with large volume of data and generate insights in real-time.

Some examples of this scenario are:
- Searching: In a large, distributed database, search for a specific information and provide result in real time (eg. Search through National Database using fingerprint and identify a person in Realtime)
- Distinct: Select “distinct” items in huge volume of data and provide results in real-time (eg. Allow users to choose and create “unique” user id to become a member in online platform like Twitter, Gmail etc.)
- Counting: Frequency counting of unique elements from a large stream of real time data. (Eg. In Twitter, identify the frequencies of each hashtag and find the most frequent one)
- Ranking: Identify the data pattern and rank them in the necessary statistical order required (eg: Monitor Realtime Credit Card transactions and identify the degree of outlier rank)
A Data algorithm is a combination of following items but not always necessary to have all of these.
- A hash algorithm
- A counter or register (In-memory datastores)
- A probability-based model to calculate final value
Leveraging Data Algorithms for Real-Time Insight Generation: Techniques and Best Practices
Implementing Real-Time Analytics: Strategies for Processing Large Data Volumes with Efficiency
Dynamic Insight Generation: Enhancing Decision-Making with Real-Time Data Algorithms
Optimization Techniques: Maximizing Performance in Real-Time Data Processing with Advanced Algorithms
Let’s understand a simple data algorithm for “Counting”. Based on the data size, we need to use suitable parameters and customize the values. This design methodology is key for the success of algorithm and is based on the data.
For example, let’s assume following stream of input data contains various hashtags.
There are 20 hashtags in this stream,

In this step, we choose two critical parameters.
- Hash algorithms. For our example let’s assume we will take two hash algorithms (I will not be discussing the hash algorithms here due to technical complexity)
- Hash Counter size: For our example, let’s use counter size as 5.
Now with this information, we will understand our Data Algorithm in two steps.
In this step, we use our Hash algorithms and get a constant single digit hash value.
For our example,
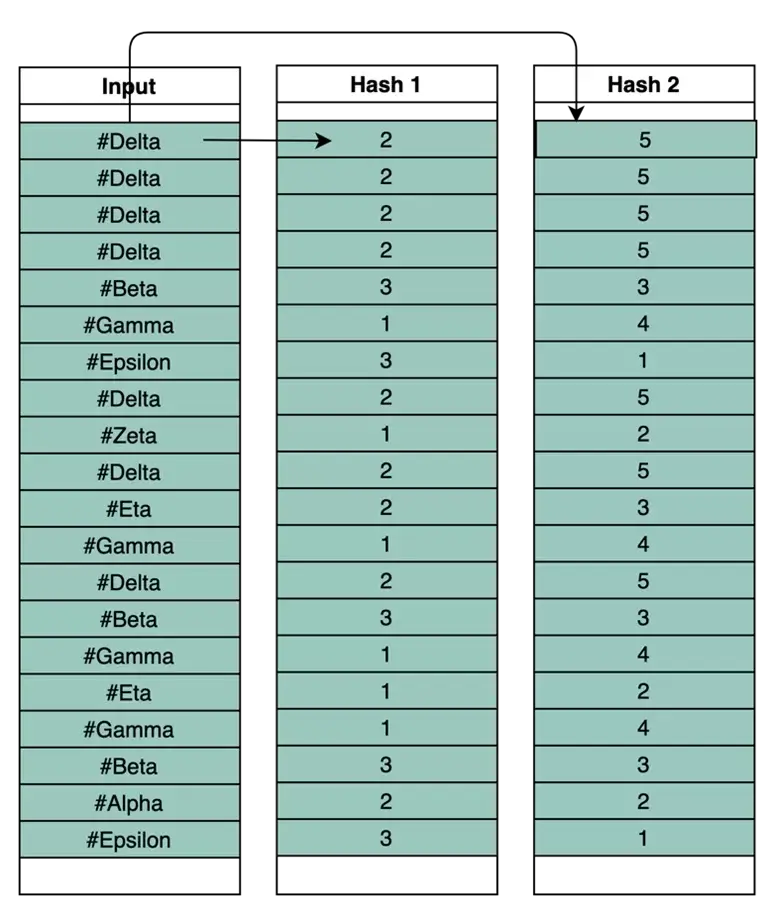
You can observe that the hash values are all between 1 to 5, because we chose 5 as the “counter size”. The hash value is always consistent for the same “Input Text (Hashtag)”.
Step 2 (Counting):
Each hashtag is converted into appropriate values based on two Hash algorithms. These values are then encoded into the Hash Counters as follows.
For hashtag “#Delta”, the Hash algorithm 1 (H1) gave value of 2 and Hash algorithm 2 (H2) gave value of 5.
Let’s assume the following.
At the beginning the “hash registers” will be as follows.
| Hash Values | Registers | ||||
| 1 | 2 | 3 | 4 | 5 | |
| h1 | 0 | 0 | 0 | 0 | 0 |
| h2 | 0 | 0 | 0 | 0 | 0 |
After processing first #delta, the hash “hash registers” will be as follows.
| Hash Values | Registers | ||||
| 1 | 2 | 3 | 4 | 5 | |
| h1 | 0 | 1 | 0 | 0 | 0 |
| h2 | 0 | 0 | 0 | 0 | 1 |
Because ‘h1’ value is 2 and ‘h2’ value is 5, the corresponding “hash registers” are incremented by 1.
After processing the first #delta hashtags, the “hash registers” will look as follows.
| Hash Values | Registers | ||||
| 1 | 2 | 3 | 4 | 5 | |
| h1 | 0 | 4 | 0 | 0 | 0 |
| h2 | 0 | 0 | 0 | 0 | 4 |
Then comes, #beta which is a different value. For this, h1 value is 3 and h2 value is 3. After update, the counter will look as follows.
| Hash Values | Registers | ||||
| 1 | 2 | 3 | 4 | 5 | |
| h1 | 0 | 4 | 1 | 0 | 0 |
| h2 | 0 | 0 | 1 | 0 | 4 |
After hashing all the data, the counter will look as below.
| Hash Values | Registers | ||||
| 1 | 2 | 3 | 4 | 5 | |
| h1 | 5 | 10 | 5 | 0 | 0 |
| h2 | 2 | 2 | 5 | 4 | 7 |
Count results:
Now, if we want to count how many times #epsilon occurred in the stream, by using the same hash function, we get h1 as 3 and h2 as 1. When we check these “hash registers”, the corresponding values are (5, 2).
Let’s say that our simple probabilistic model chooses the minimum of the values as the final output.
The minimum of these values is 2. Which denotes the count.
So, the #epsilon occurs 2 times in this stream. Using the same method, we can find that #delta occurs 7 times etc.
This is a simple count algorithm. If we want to count a specific hashtag or topic in real time, rather than querying the entire database, using these counters and with simple hash calculations, the frequency value can be calculated very fast.
In any Data problem, the success of outcome is driven by data and not by the algorithm. While algorithms provide a basic framework, the values associated with them must be chosen by experts while designing.
Some of the key considerations on designing Data Algorithm are
- Design appropriate hash algorithms (usually one-way hashing and have high collision resistant) and number of hash algorithms required
- Designing the size of the “hash registers”
- Probabilistic model and data structures to choose the output value (since hash algorithms compress huge population of data into a small register, there will be overlaps and suitable probabilistic model will help in retrieving result with higher probability)
How USEReady Can Help
USEReady is an award winning, end-to-end data transformation consultancy that applies best practices and technology to deliver solutions that help our customers succeed with data. We bring deep expertise and skills in design & implementation of large-scale data solutions, Data Science and Machine Learning (DSML) solutions. Through our holistic approach, experience in modern data platforms and our Analytics Maturity Framework we help customers navigate through the intricacies of ML journey and accelerate their adoption and deployment.
