Unlocking Real-Time Data Flow with Salesforce CDC
A Comprehensive Guide to Data Pipelines Using Salesforce CDC
Enhancing Data Streaming with Salesforce Change Data Capture
Understanding Salesforce Change Data Capture (CDC)
Key Steps to Building Real-Time Data Pipelines
Benefits of Using Salesforce CDC for Data Integration
Best Practices for Scalable Pipeline Architecture
Setting Up Salesforce CDC for Real-Time Integration
Common Challenges in Real-Time Data Pipelines
Optimizing Pipeline Performance with Salesforce CDC
Tools and Techniques for Effective Data Streaming
Today’s digital economy demands agility, especially in how businesses manage and act on their data. Real-time data processing is critical for businesses to make timely decisions and maintain their competitive edge. Salesforce Change Data Capture (CDC) facilitates real-time tracking of changes to Salesforce data, which can then be processed using powerful frameworks like Apache Spark and Kafka. In this blog we dive into how integrating CDC with Apache Kafka can empower organizations to create a highly efficient, real-time data pipeline.
What’s Salesforce CDC?
The Salesforce Change Data Capture (CDC) feature enables real-time tracking of changes to Salesforce records, including inserts, updates, deletions, and undeletions. It ensures data synchronization across systems that depend on Salesforce data. For example, organizations often integrate Salesforce with other systems, which rely on up-to-date data for smooth operations. CDC ensures real-time data updates within your Salesforce environment.
With Salesforce CDC, a change event is created whenever a Salesforce record is created, updated, deleted, or undeleted. This event contains details about the changes, such as updated fields and header information about the change.
Salesforce CDC can be implemented in multiple ways. Native solutions offer basic streaming capabilities but come with limitations, while more flexible options provide enhanced scalability and adaptability.
How Salesforce CDC works?
Data in Salesforce can be synchronized with external systems through Change Data Capture (CDC). This can be beneficial for analytics or to update data in a data warehouse.
Change Data Capture in Salesforce is implemented through an event-driven architecture. When data is changed in Salesforce, a change event is published to the Salesforce event bus through a create, update, delete or undelete operation. From here, the event can be consumed by subscribers of that channel. The architecture can be seen as a Publisher/Subscriber model. Changes in a Salesforce record trigger a notification to all subscribers who desire to know about such changes.
This is preferable to the alternative pull technology approach where a client periodically sends queries to the server asking for recent changes in data. This approach is a much less efficient way to replicate Salesforce data. The streaming of change events in Salesforce means that data is synchronized in near real-time. Live data is then available in downstream target systems that are integrated with Salesforce.
Here are the steps to implement CDC in Salesforce:
- Enabling CDC and selecting objects
- Subscribing to the event channel
- Building the jar file
- Accessing Salesforce events
- Subscribing to events
- Creating new objects
- Monitoring the terminal
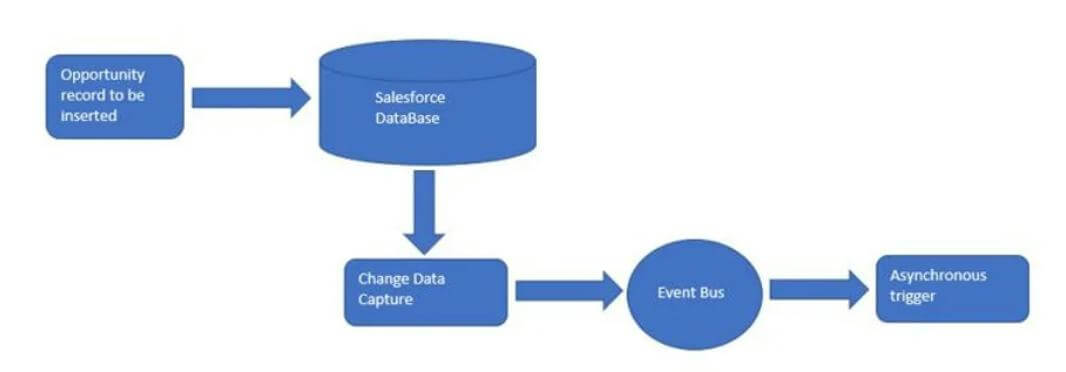
Platform Event Flow
Salesforce to KAFKA. How Salesforce Pushes Topics to KAFKA
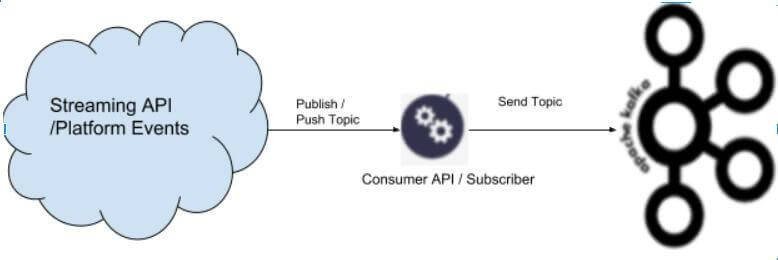
What is Kafka?
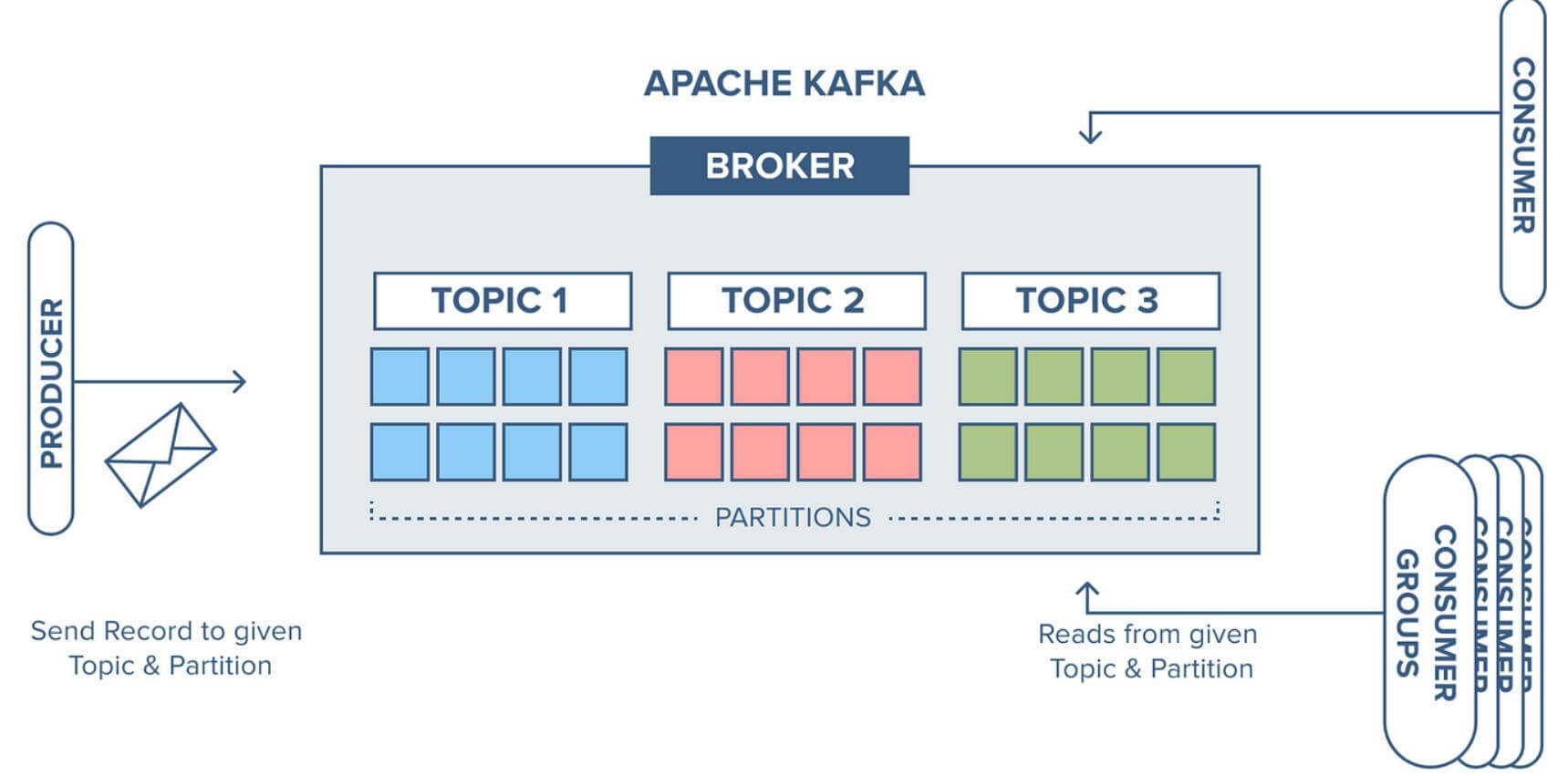
Apache Kafka is a distributed publish-subscribe messaging system and a robust queue that can handle a high volume of data and enables you to pass messages from one endpoint to another. Kafka is suitable for both offline and online message consumption. Kafka messages are persisted on the disk and replicated within the cluster to prevent data loss. Kafka is built on top of the ZooKeeper synchronization service. It integrates very well with Apache Storm and Spark for real-time streaming data analysis.
Benefits of Kafka
The main benefits of Kafka are:
Reliability
Kafka is distributed, partitioned, replicated and fault tolerant.
Scalability
Kafka messaging system scales easily without downtime.
Durability
Kafka uses a Distributed commit log which means messages persist on disk as fast as possible, hence it is durable.
Performance
Kafka has high throughput for both publishing and subscribing messages. It maintains stable performance even when many TB of messages are stored.
Steps to Start Kafka
Step 1
Start Zookeeper
bin\windows\zookeeper-server-start.bat config\zookeeper.propertiesStep 2
Start Kafka Server
bin\windows\kafka-server-start.bat config\server.propertiesStep 3
Create Kafka Topic
bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic_name Step 4
List of Kafka Topic
bin\windows\kafka-topics.bat --list --zookeeper localhost:2181 Step 5
Start Kafka Producer
bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic testing Step 6
Start Kafka Consumer
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic logs --from-beginning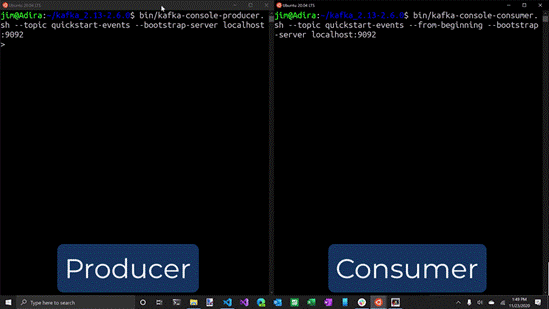
Integrating Salesforce CDC with Kafka allows you to build a robust real-time data processing pipeline. This setup ensures that your data is always up to date, allowing you to make timely, data-driven decisions. Kafka’s scalability and flexibility make it an ideal choice for managing large volumes of streaming data.
Additional Resources

