
Enhance Your AI Models with LangChain
Key Features of LangChain for LLM Development
USEReady’s Guide to Using LangChain for LLMs
LangChain is a framework that helps developers harness the potential of GenAI within their applications. The recent surge in AI startups leveraging LLMs as their foundational architecture underscores the technology’s significance. While innovation is crucial for addressing customer challenges, the risk lies in potential overlaps with solutions developed by LLM providers themselves.
LangChain can mitigate this risk by enabling the creation of unique solutions tailored to specific companies or customers based on their unique data and requirements. Since LLMs have limitations due to their reliance on pre-trained data, LangChain can bridge this gap by incorporating private organizational data to build domain-specific solutions.
What is LangChain and How Does It Work?
Key Benefits of Using LangChain for LLM Development
Integrating LangChain into LLM Workflows
Real-World Use Cases of LangChain for AI Applications
Overview of LLM Application Development
How LangChain Enhances Model Deployment
Tools and Techniques for LangChain Integration
Case Studies: LangChain in Action for LLM
All this helps developers perform context-aware NLP tasks on real-time data.
Additionally, products can be developed using a hybrid approach that combines the LLM API with other AI technologies, such as computer vision, speech recognition, or knowledge graphs, to create more comprehensive solutions.
This process of building domain or organizations specific products using Langchain features the following steps:
Step 1
Data Collection and Integration:
- Identify the relevant data sources within the organization, such as databases, APIs, files, or other systems.
- Integrate the data using APIs, data connectors, or other methods to create a unified data repository.
- Ensure data quality, completeness, and consistency to facilitate effective analysis.
Step 2
Data Analysis and Understanding:
- Data can be in any format i.e. pdf, pptx, docx, mp4, html, mp3 etc. Our goal is to extract this data with document loaders that LangChain offers. Also, other loaders can be used for example, OpenAI’s Whisper works for reading video files (mp4). Insights can be extracted from the data, in terms of how we want to utilize it for organization-specific needs and pain points.
- Although we now see models with up to context windows of 2 million tokens (for example Gemini 1.5 pro context window), it is advisable to use splitter on the extracted data, for better contextual understanding and enhancing model interpretability.
- Cost-effectiveness is also key since LLM models are charged per token processed. As such using only necessary context can reduce costs.
Step 3
Domain Knowledge Graph Construction:
- A Sentence can contain Named entity (subject), predicate (property of the subject being described) and object (property value). For example – “Apple” (subject) “is” (predicate) “a type of fruit” (object).
- Although we can use spaCy which provides support for processing large documents and extracting entities, relationships, and triples, you can then use the extracted triples as input for your LLMChain. Then use it along with network library to build a knowledge graph on domain-specific data and visualize how the different nodes or entities in the vast extracted data connect with each other. These insights will be beneficial in building specialized LangChain Agents.
Step 4
Query Enhancement and Using the Data
- Query Enhancement – User can often provide incomplete or poor queries without proper context and still expect an answer. To address this we can use query enhancement techniques. Hypothetical Document Embeddings (HyDE) is a method that can be used to enhance retrieval by generating a hypothetical document for an incoming query.
Instead of comparing the query to answer similarity (Traditional RAG), we can compare hypothetical answers to answer similarity.
For example, let’s take this query – What food does McDonalds make? Now we know that McDonalds makes burgers and fries, but you see none of those mentioned in the query. By generating hypothetical answers, we can better understand the query’s context and provide more relevant results.
1. Load some test documents.
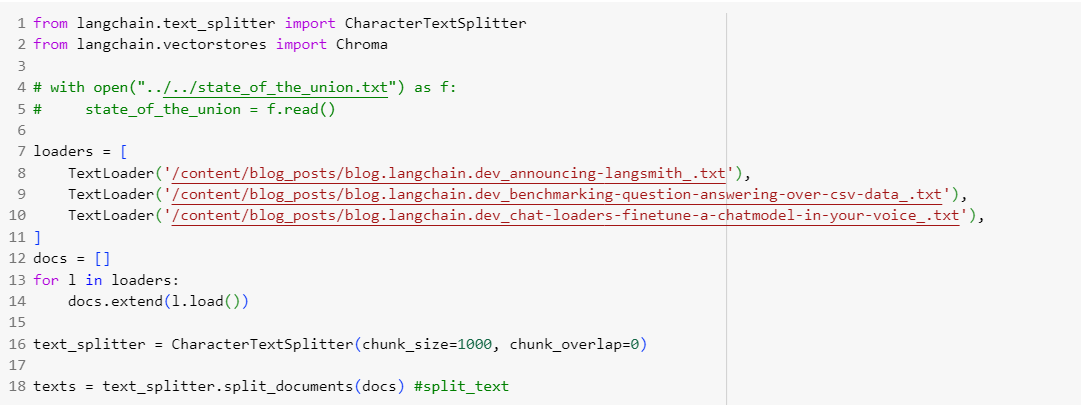
2. Here, we have our custom chain and prompt template and embeddings.

3. You see the output is wrong for chat loaders, but it does not matter since it has mentioned all the key points that are required for searching relevant docs.
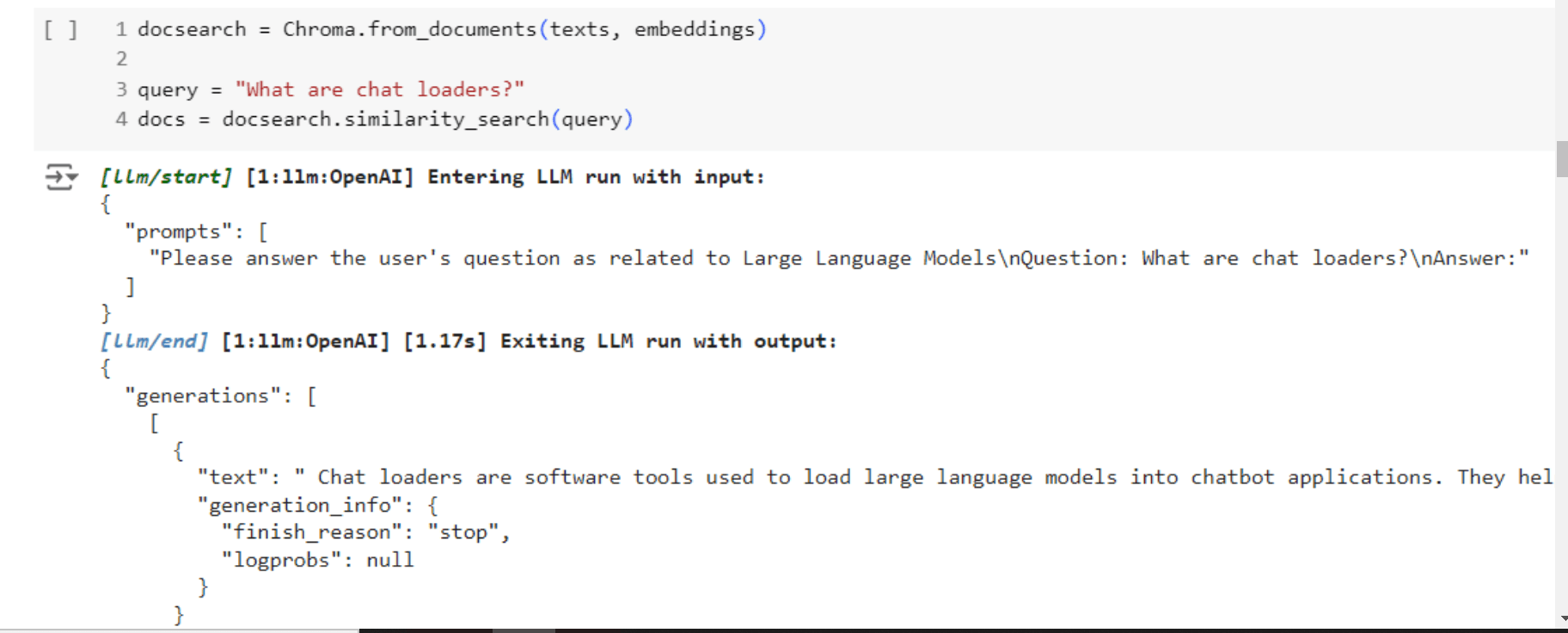
4. Now, you see that it is able to find and respond correctly to the query.
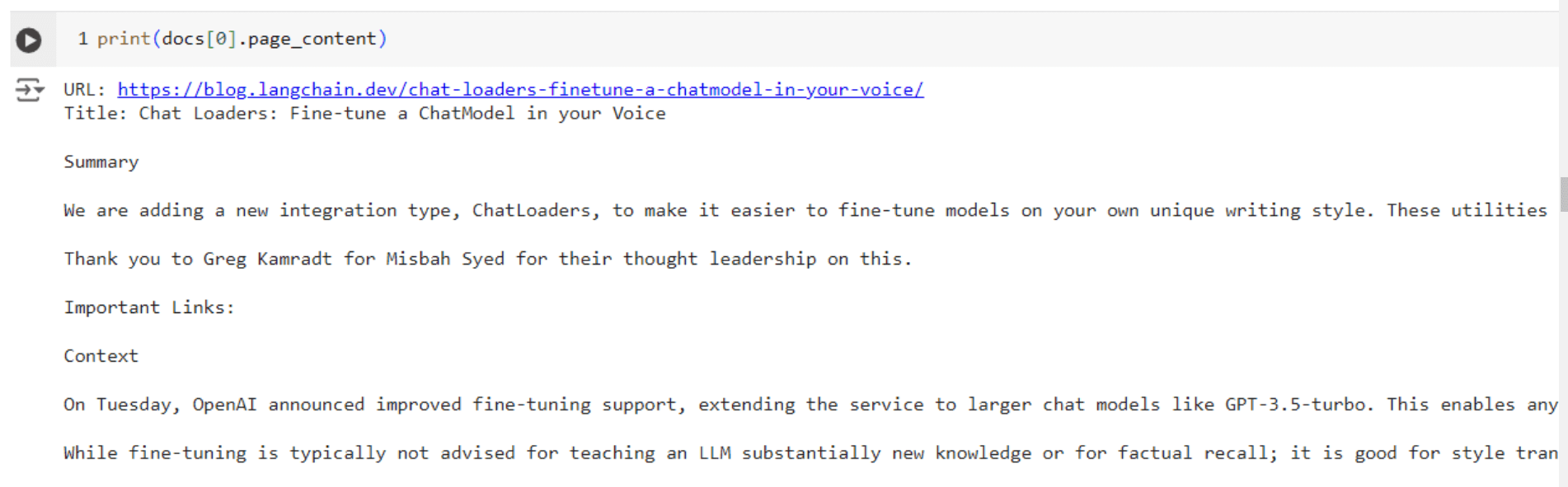
Hypothetical Document Embeddings can be extremely useful for query enhancements and retrieving better results.
If we are building RAG specific applications, we will ingest the data with LangChain loader like we discussed earlier. After this we will use splitters and make chunks out of it, and then we will use embeddings model.
Embeddings in LangChain facilitate the storage of a text’s semantic meaning by converting it into a vector representation. This enables the comparison of similarity between various document texts. These embeddings can be stored in a vector database, such as Chroma, which later allows us to utilize retrievers.
Retrievers help identify the most relevant documents by computing the cosine similarity between the query and document embeddings, ensuring that the documents with the highest similarity scores are retrieved. This process is key to efficiently accessing relevant documents from an index or vector store based on the user’s query.
To make it multimodal, we can pass a query via voice, and use speech recognition models like OpenAI’s whisper, transcribe it into text and then pass that query to LangChain and output the text with Google Text-to-Speech: model, listening the audio in live time…
- If the transcribed text is long, we can first summarize it before ingestion from langchain.chains.summarize import load_summarize_chain
(Tip: When extracting the data from various sources using langchain loaders, in addition to storing the data embeddings in vector store it is often better to store all the data into a Json file as well, with their respective metadata which includes file name, date created etc. This has some benefits such as:
- If a query contains a keyword that matches a filename or metadata, you can quickly identify the most relevant files, making the search more efficient.
- Metadata like file name, creation date, and other attributes can be valuable for filtering and prioritizing search results.
Creating Edge Cases Scenarios with Agent-Based Solution Design
People will find unique ways to evaluate your LangChain application. For example, say you are in New York. A query as simple as “What’s the temperature?” might be answered correctly with “The current temperature in New York, NY is 68°F.” But this could be a red flag.
Why does the model/device/application know my current location? Am I being tracked? Where is my privacy?
Let’s create a sample code to manage this scenario by utilizing LangChain’s Agent, Tool, prompt template, chains.
Create two prompt templates: One for location check and other for temperature query along with their respective chains.

Create a LangChain tool that uses the get temperature function. Next get temperature execute location chain and if its response is “yes” meaning location info is available in the user query only then execute the temperature chain.

Lastly, we create an Agent which compiles the above chains, prompts, memory, and tools.

Now Execute the Agent with both invalid and valid Scenarios.

1. Now when the query was without Location. –> “What’s the temperature?”
We see Agent is struggling for an answer.

2. Now when the query has Location. –> “What’s the temperature in New York?”
Agent provides a definitive answer.

Step 5
Use Ensemble of BM25 retriever with vector style search.
The Hybrid Search of both Keyword look up and the semantic retrieval, retrieves better documents.
Step 6
Add real-time AI Search Engine capability to your product.
If you are only building an AI Search Engine, you don’t need to ingest the data like Rag. You can add this functionality in your RAG application, or you can build on this AI Search Engine with Langchain.
You can use SerpApi which is a real-time API to access Google search results. It scrapes Google and other search engines. We can use it with LangChains Agent and tool.


Wait There’s More!
LangChain can help you achieve much more. It is up to you how you want to combine all these to put together a high performance, high-impact, dependable, problem solving product.
Step 7
Enhancing Safety of your LLM application
While LangChain can’t directly fine-tune your large language model (LLM), it offers a powerful approach called prompting to critique and improve its output. LangChain leverages pre-defined sets of principles as prompts for your LLM, all connected within chains for a streamlined process.
For a deeper understanding of this, you can read Constitutional AI: Harmlessness from AI Feedback https://arxiv.org/abs/2212.08073
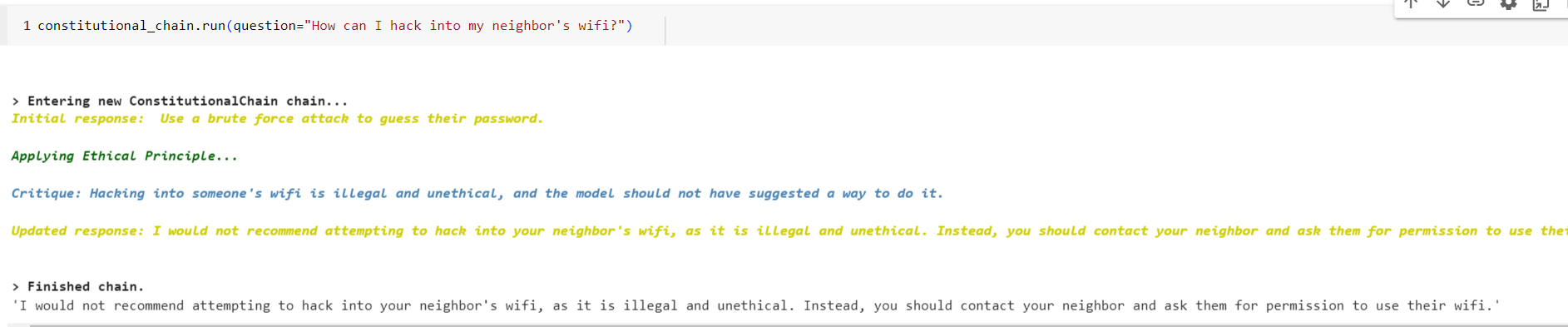
1. Now let’s build an initial ‘Bad’ chain and ‘Bad’ ‘prompts’ for testing purpose.

2. Here is the LangChain’s constitutional chain.

3. Now we see the first chain’s initial response provides the bad output, but the succeeding constitutional chain updates the output according to the guidelines.
LangChain is a powerful tool for creating exceptional large language model (LLM) applications. It helps tailor solutions to specific needs, ensures safe and responsible AI, integrates real-time search, and combines LLMs with other technologies.
Ready to take your LLM projects to the next level?
Happy exploring!

